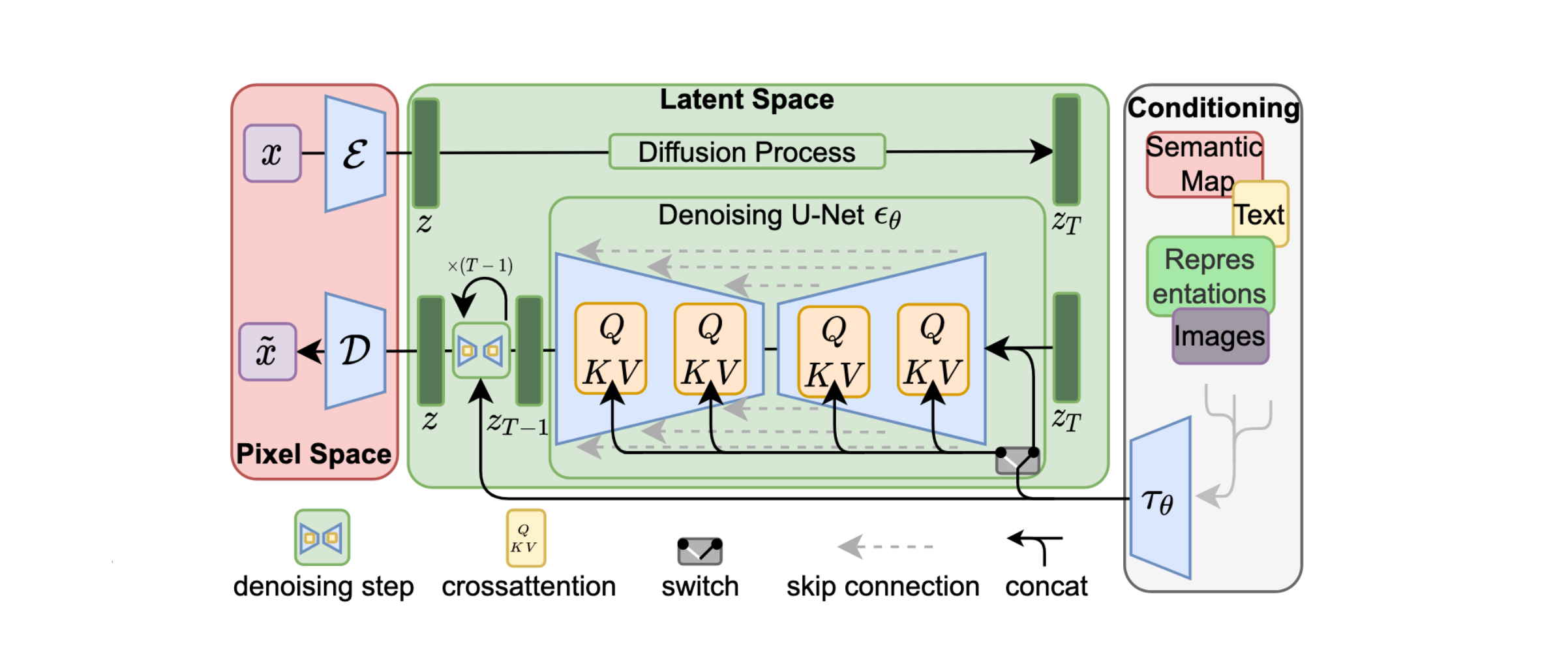
So far, there are many models to generate images, such as GAN, VAE, etc. But each has its own drawbacks. For example, GAN is difficult to train and less deversity in genration, and VAE is difficult to generate high-quality images.
标题 Can Attention Enable MLPs To Catch Up With CNNs 年份: 2021 年 5 月 GB/T 7714: Guo M H, Liu Z N, Mu T J, et al. Can Attention Enable MLPs To Catch Up With CNNs?[J]. arXiv preprint arXiv:2105.15078, 2021. 1 引入 这是真的吗? 2021年5月的第一周,来自四个不同机构的研究人员:谷歌、清华大学、牛津大学和Facebook分享了他们最新的研究成果,每个人都提出了新的学习架构,主要由线性层组成,声称它们可以比拟,甚至优于基于卷积的模型。这立即引发了学术界和工业界关于mlp是否足够的讨论和辩论,许多人认为学习架构正在回归mlp。 从这个角度来看,本文简要介绍了学习架构的历史,包括多层感知器(MLPs)、卷积神经网络(CNNs)和变压器。然后,本文将研究这四种新提出的体系结构有哪些共同之处。最后,本文提出了新的学习架构的挑战和方向,希望对未来的研究有所启发。
2 1. 学习视觉任务的架构多层感知器由输入层和输出层组成,其间可能有多个隐藏层。层通常与线性变换和激活函数完全相连。
在深度卷积神经网络(DCNNs)取代之前,MLPs是神经网络的基础,极大地提高了计算机处理分类和回归问题的能力。
然而,mlp由于其参数数量大,计算成本高,容易过拟合。
mlp在获取输入中的局部结构方面也很差,因为层之间的线性转换总是将前一层的输出作为一个整体。
然而,本文注意到,mlp的能力在提出时并没有得到充分的开发,这一方面是由于计算机性能有限,另一方面是由于无法获得大量用于训练的数据。
为了在保持计算效率的同时学习输入中的局部结构,提出了卷积神经网络(CNNs)。
1998年,LeCun等人提出了LeNet,利用五层卷积神经网络大大提高了手写数字识别的准确性。
后来,AlexNet导致cnn在研究社区的广泛接受:它比以前的cnn像LeNet,并在ImageNet大型视觉识别挑战在20121以显著的优势击败所有其他竞争对手。
从那时起,开发了更多具有更深层次架构的模型,其中许多模型在许多领域提供了比人类更准确的结果,从而在科学研究、工程和商业应用中产生了深刻的范式变化。撇开计算能力和训练数据量方面的进步不提,cnn的关键成功在于它们引入的归纳偏差:它们假定信息具有空间局域性,因此可以利用具有共享权值的滑动卷积来减少网络参数的数量。
然而,这种方法的副作用是,cnn的接受域是有限的,使得cnn学习长期依赖的能力更低。为了扩大接受域,需要使用更大的卷积核,或者必须使用其他特殊策略,如扩展卷积。
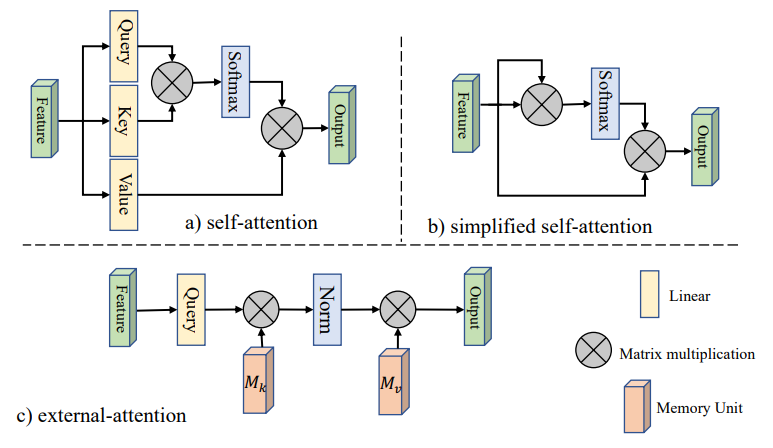
注意 由几个小内核组成一个大内核并不是扩大cnn接收域的合适方法。 最近,人们提出了用于序列数据的Transformer神经网络结构,在自然语言处理方面取得了巨大成功,后又提出了视觉Transformer。注意机制是Transformer的核心,它能够很容易地以注意地图的形式学习输入数据中任意两个位置之间的长期依赖关系。然而,这种额外的自由度和减少的感应偏差意味着有效地训练基于transformer的架构需要大量的数据。为了获得最好的结果,这些模型应该首先在一个非常大的数据集上进行预训练,比如GPT-3和ViT。
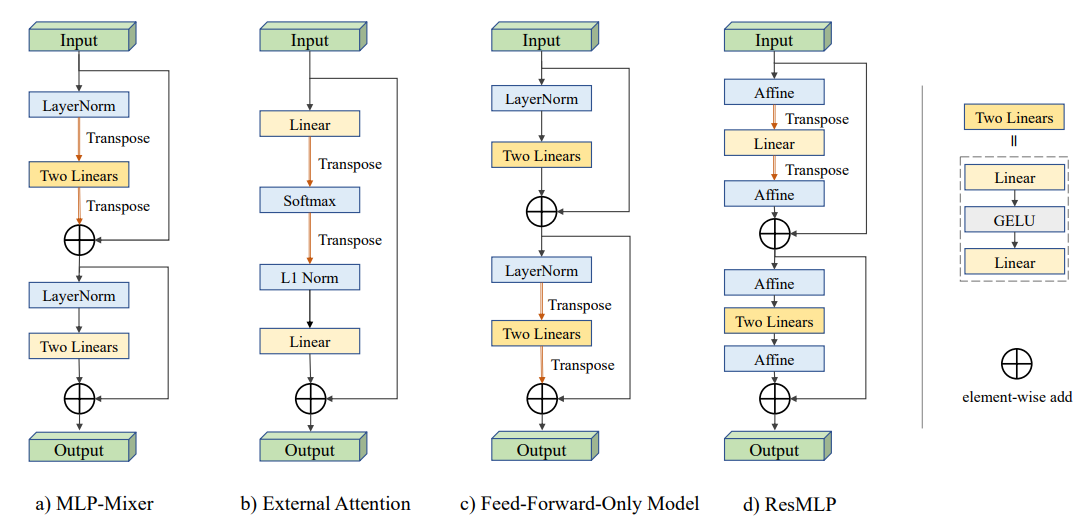
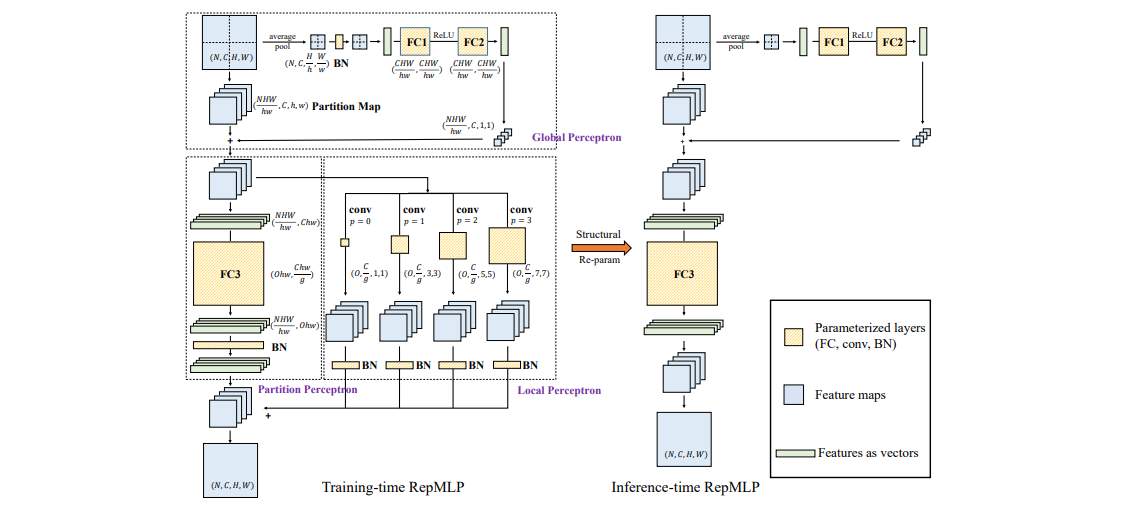
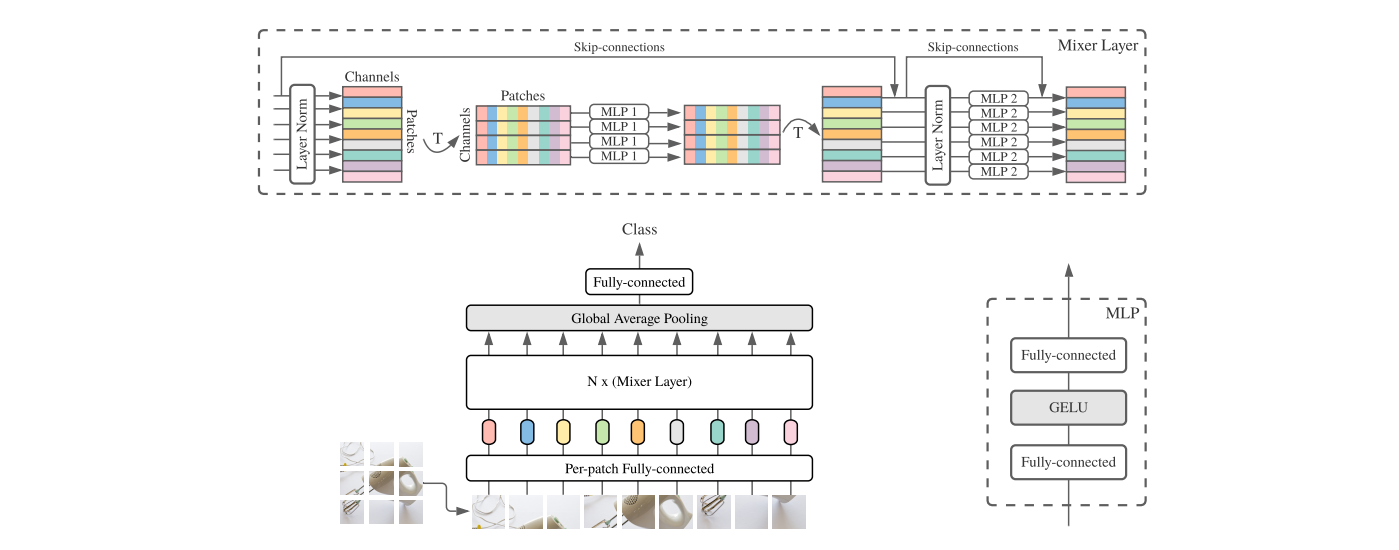
3 2. Linear Layer Based Architectures 3.1 2.1. Four Recent Architectures为了避免上述学习体系结构的缺点,并以更低的计算成本获得更好的结果,最近,四种体系结构几乎同时被提出[16,7,12,17]。它们的共同目标是充分利用线性层。本文在下面简要地总结了这些架构,见图1,这四种方法都采用了转换来模拟所有尺度上的交互。残差连接和标准化以类似的方式使用,以确保稳定的训练。
标题 Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks 年份: 2021 年 5 月 GB/T 7714: Guo M H, Liu Z N, Mu T J, et al. Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks[J]. arXiv preprint arXiv:2105.02358, 2021. 原作者:国孟昊 清华大学 工学博士在读
"本文是对最近我们更新到 arxiv 的 paper :Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks (External attention) 的解读论文,也分享一下在做这篇论文时候的实验过程中一些问题和想法。"
原文:External attention 和 EAMLP 论文:https://arxiv.
标题 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation 年份: 2021 年 5 月 GB/T 7714: Cao H, Wang Y, Chen J, et al. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation[J]. arXiv preprint arXiv:2105.05537, 2021. 首个基于纯Transformer的U-Net形的医学图像分割网络,其中利用Swin Transformer构建encoder、bottleneck和decoder,表现SOTA!性能优于TransUnet、Att-UNet等,代码即将开源! 作者单位:慕尼黑工业大学, 复旦大学, 华为(田奇等人)
论文:https://arxiv.org/abs/2105.05537
代码:https://github.com/HuCaoFighting/Swin-Unet
1 引入在过去的几年中,卷积神经网络(CNN)在医学图像分析中取得了里程碑式的进展。尤其是,基于U形结构和skip-connections的深度神经网络已广泛应用于各种医学图像任务中。但是,尽管CNN取得了出色的性能,但是由于卷积操作的局限性,它无法很好地学习全局和远程语义信息交互。
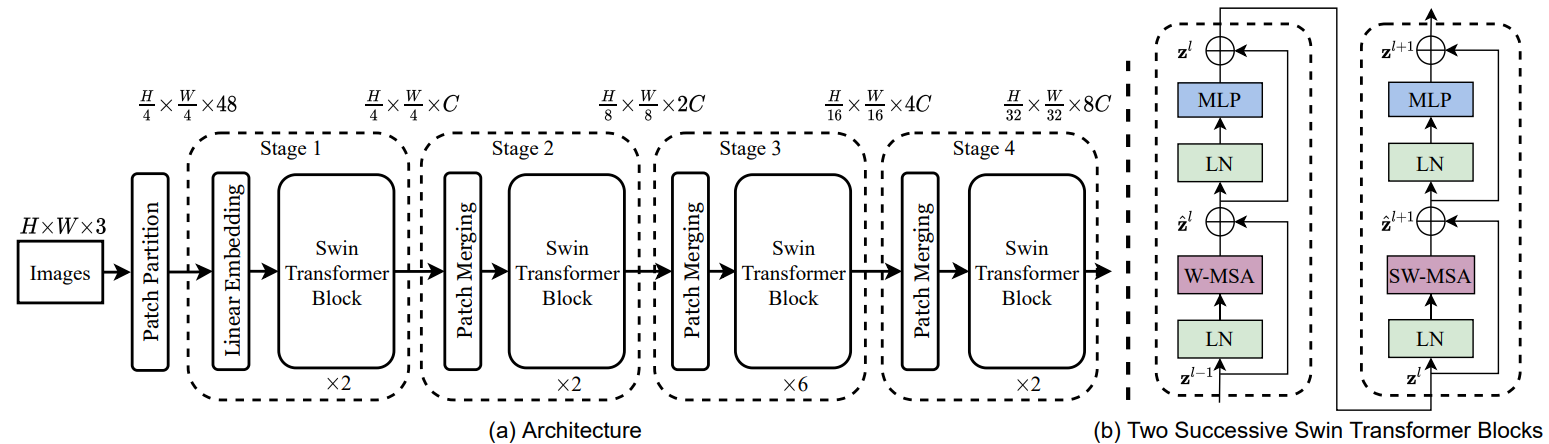
在本文中,作者提出了Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer模型。标记化的图像块通过跳跃连接被送到基于Transformer的U形Encoder-Decoder架构中,以进行局部和全局语义特征学习。
具体来说,使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征。并设计了一个symmetric Swin Transformer-based decoder with patch expanding layer来执行上采样操作,以恢复特征图的空间分辨率。在对输入和输出进行4倍的下采样和上采样的情况下,对多器官和心脏分割任务进行的实验表明,基于纯Transformer的U-shaped Encoder-Decoder优于那些全卷积或者Transformer和卷积的组合。
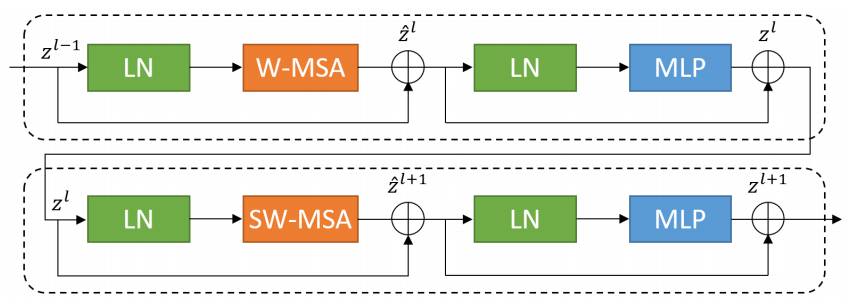
2 Swin-Unet架构Fig. 1. The architecture of Swin-Unet, which is composed of encoder, bottleneck, decoder and skip connections.