机器学习算法总结

1 线性回归与逻辑回归
线性回归和逻辑回归是 2 种经典的算法:一文看懂线性回归(3个优缺点+8种方法评测) - easyAI 人工智能知识库
二者的一些区别:
- 线性回归只能用于回归问题,逻辑回归虽然名字叫回归,但是更多用于分类问题
- 线性回归要求因变量是连续性数值变量,而逻辑回归要求因变量是离散的变量
- 线性回归要求自变量和因变量呈线性关系,而逻辑回归不要求自变量和因变量呈线性关系
- 线性回归可以直观的表达自变量和因变量之间的关系,逻辑回归则无法表达变量之间的关系
8 种线性回归方法速度测评:Data science with Python: 8 ways to do linear regression and measure their speed (freecodecamp.org)
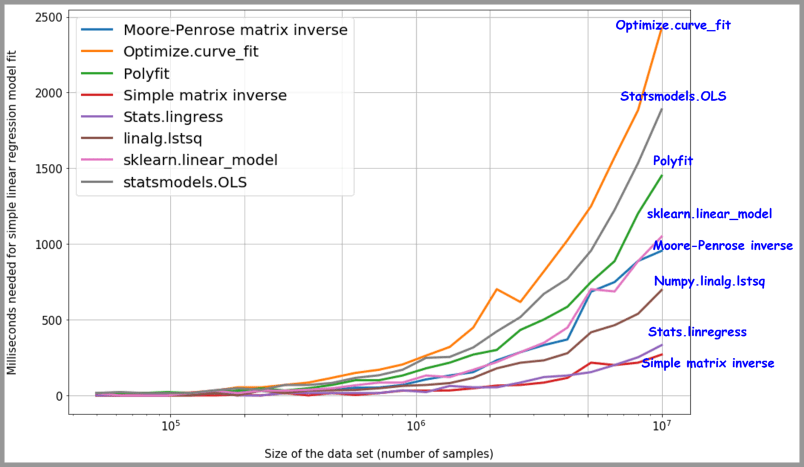
2 Adaboost算法
Adaboost是一种集合技术,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。这是通过从训练数据构建模型,然后创建第二个模型来尝试从第一个模型中纠正错误来完成的。添加模型直到完美预测训练集或添加最大数量的模型。
AdaBoost是第一个为二进制分类开发的真正成功的增强算法。这是理解助力的最佳起点。现代助推方法建立在AdaBoost上,最着名的是随机梯度增强机。
AdaBoost算法优点:
-
很好的利用了弱分类器进行级联;
-
可以将不同的分类算法作为弱分类器;
-
AdaBoost具有很高的精度;
-
相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重;
Adaboost算法缺点:
-
AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定;
-
数据不平衡导致分类精度下降;
-
训练比较耗时,每次重新选择当前分类器最好切分点;
3 朴素贝叶斯 Naive Bayes classifier(NBC)
该模型由两种类型的概率组成,可以直接根据训练数据计算:
- 每个班级的概率
- 给出每个x值的每个类的条件概率。
一旦计算,概率模型可用于使用贝叶斯定理对新数据进行预测。当数据是实值时,通常假设高斯分布(钟形曲线),以便轻松估计这些概率。

朴素贝叶斯被称为朴素,因为它假设每个输入变量是独立的。这是一个强有力的假设,对于实际数据是不现实的,然而,该技术对于大范围的复杂问题非常有效。
实验测试:四种经典机器学习算法测试——Bayes, SVM, 决策树, K-Means - Yuexin’s Blog (wyxogo.top)
3.1 关于贝叶斯公式
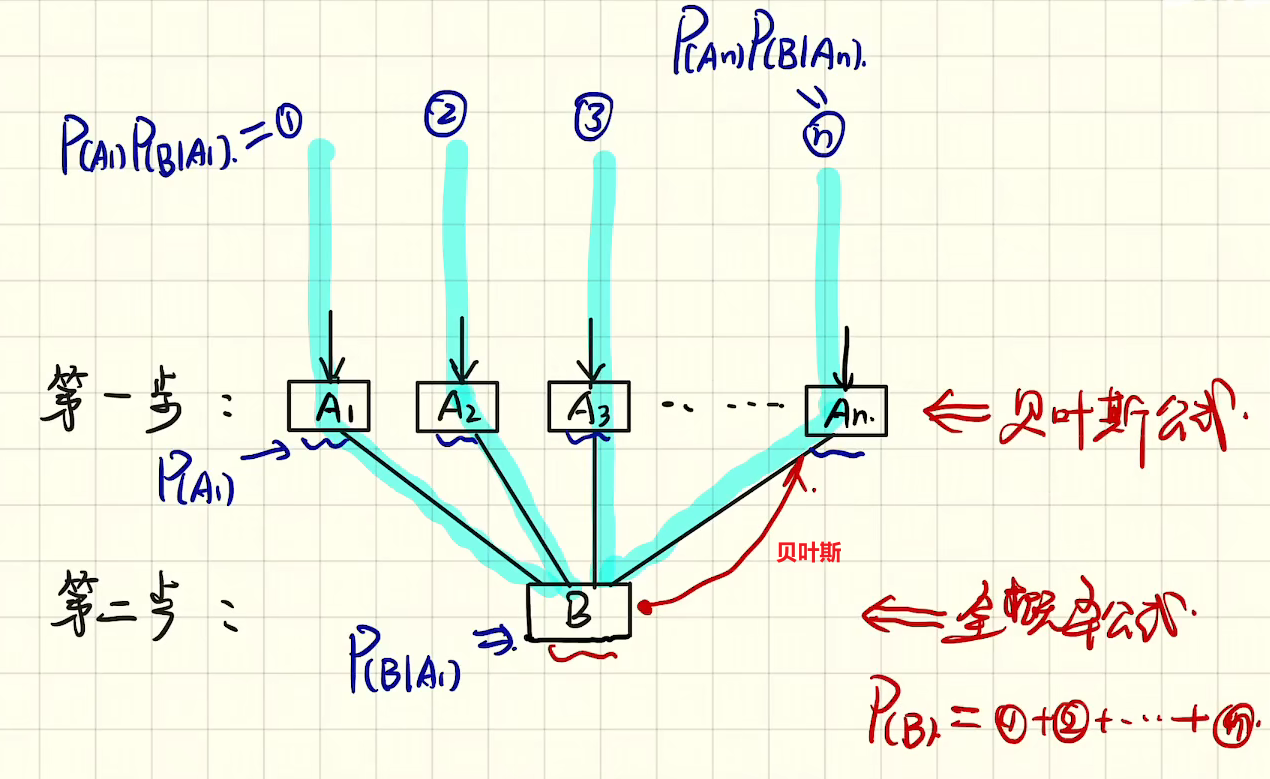
全概率公式
$$P(B)= P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+...+P(A_n)P(B|A_n)$$贝叶斯公式
$$P(A_i|B)=\frac{P(A_i)P(B|A_i)}{\sum_{j=1}^{n}P(A_j)P(B|A_j)}=\frac{P(A_i)P(B|A_i)}{P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+...+P(A_n)P(B|A_n)}=\frac{P(A_i)P(B|A_i)}{P(B)}$$4 决策树 Decision tree(DT)
决策树是一种解决分类问题的算法,采用树形结构,使用层层推理来实现最终的分类
主要有以下组成:
- 根节点:包含样本的全集
- 内部节点:对应特征属性测试
- 叶节点:代表决策的结果
预测时,在树的内部节点处用某一属性值进行判断,根据判断结果决定进入哪个分支节点,直到到达叶节点处,得到分类结果。
这是一种基于if-then-else规则的有监督学习算法,决策树的这些规则通过训练得到,而不是人工制定的。
ID3算法引入熵增益思想,使决策树更高效但只适用于分类问题
回归问题可以参考CART算法
实验测试:四种经典机器学习算法测试——Bayes, SVM, 决策树, K-Means - Yuexin’s Blog (wyxogo.top)
5 随机森林 Random Forest(RF)
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
构造随机森林的步骤:
- 随机抽样训练决策树:一个样本容量为N的样本,有放回的的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
- 随机选取属性做分裂结点属性:当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m « M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
- 重复
2直到不再分裂:决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。- 建立大量决策树构成森林:按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
6 K均值聚类
K均值思想:图像分割(Segmentation)——K-Means, 最小割, 归一化图割 - Yuexin’s Blog (wyxogo.top)
实验测试:四种经典机器学习算法测试——Bayes, SVM, 决策树, K-Means - Yuexin’s Blog (wyxogo.top)
7 支持向量机(SVM)
超平面是分割输入变量空间的线。在SVM中,选择超平面以最佳地将输入变量空间中的点与它们的类(0级或1级)分开。在二维中,可以将其视为一条线,并假设所有输入点都可以被这条线完全分开。SVM学习算法找到导致超平面最好地分离类的系数。
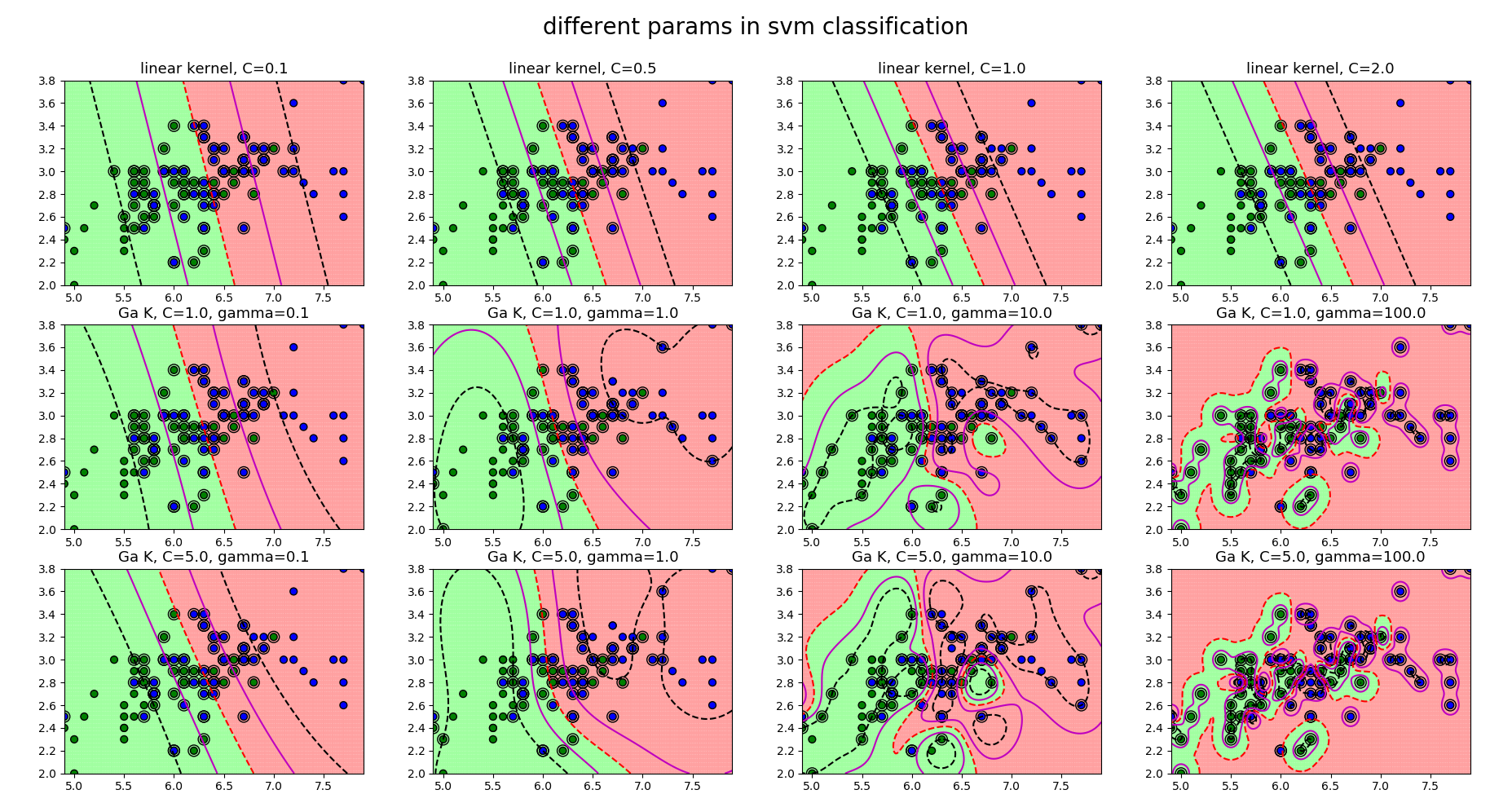
7.1 距离最大化
关于SVM分类得一个重要思想就是距离最大化,如下图所示,显然在不加入两个样本点时两个分类器得分类结果相似,单加入两个样本点后对样本点得分类截然不同。
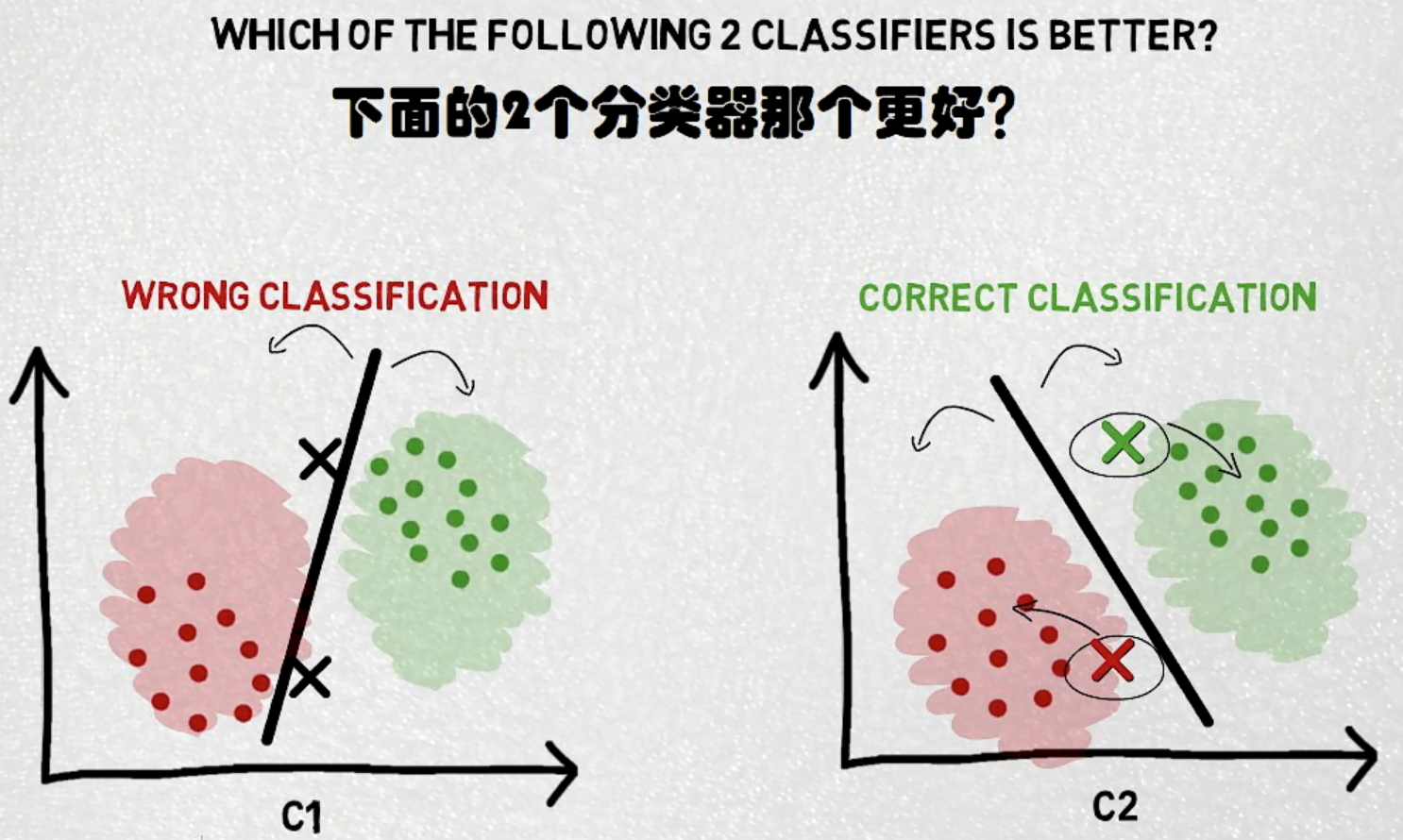
相关资源:
一文看懂支持向量机 SVM(附:6个有点+5个缺点) (easyai.tech)
(15条消息) 机器学习–svm算法一些参数调节demo_OliverkingLi的博客-CSDN博客_svm算法参数
实验测试:四种经典机器学习算法测试——Bayes, SVM, 决策树, K-Means - Yuexin’s Blog (wyxogo.top)
8 常见问题总结
8.1 什么是梯度爆炸和梯度消失?如何解决梯度消失、梯度爆炸?
梯度爆炸在反向传播过程中需要对激活函数进行求导,如果导数大于1,层与层之间的梯度连续相乘,随着网络层数的增加梯度更新将会朝着指数爆炸的方式增加。同样如果导数小于1,那么随着网络层数的增加梯度更新信息会朝着指数衰减的方式减少这就是梯度消失。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则。
解决方法:
- Pre-training+Fine-tunning: 先逐层预训练,在对整个网络微调,即整合局部最优解得到全局最优解(Hinton)
- 梯度裁剪:对梯度设定阈值
- 权重正则化,如L1,L2正则
- 使用Relu等梯度大部分落在常数上的激活函数
- Batch Normalization
- 残差连接
- LSTM的”gate“结构
