Swin Transformer论文解读与源码分析
| 标题 | Swin Transformer: Hierarchical Vision Transformer using Shifted Windows |
|---|---|
| 年份: | 2021 年 3 月 |
| GB/T 7714: | [1] Liu Z , Lin Y , Cao Y , et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows[J]. 2021. |
Swin Transformer ( Shifted window) , 它可以作为计算机视觉的通用骨干。它基本上是一个层次转换器,其表示是通过移位的窗口计算的。移位窗口方案通过将自注意计算限制在不重叠的局部窗口上,同时允许跨窗口连接,从而带来更高的效率
1 引入
Transformer尽管在CV任务有着不俗的表现,但是这是牺牲了速度与算力,这也是现在传统CNN没有被transformer取代的原因——CNN实在是太成熟了,目前业界不会冒风险并再挖坑填坑接纳transformer,而要想transformer替代CNN,必须要在各大CV任务上遥遥领先与传统CNN并且速度不亚于传统CNN,这样才会让业界重新花费代价去部署接纳transformer,这也是目前CV任务的研究热点。
Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:
-
两个领域涉及的scale不同,NLP的scale是标准固定的,而CV的scale变化范围非常大。
-
CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。
为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:
- 引入CNN中常用的层次化构建方式构建层次化Transformer
- 引入locality思想,对无重合的window区域内进行self-attention计算
2 框架结构
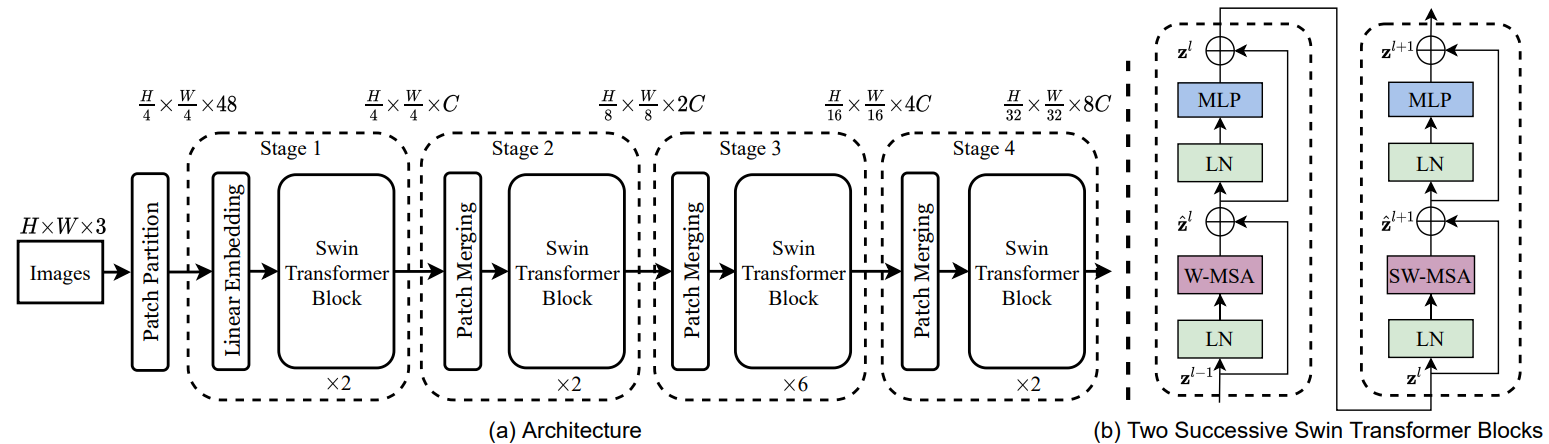
3 方法介绍
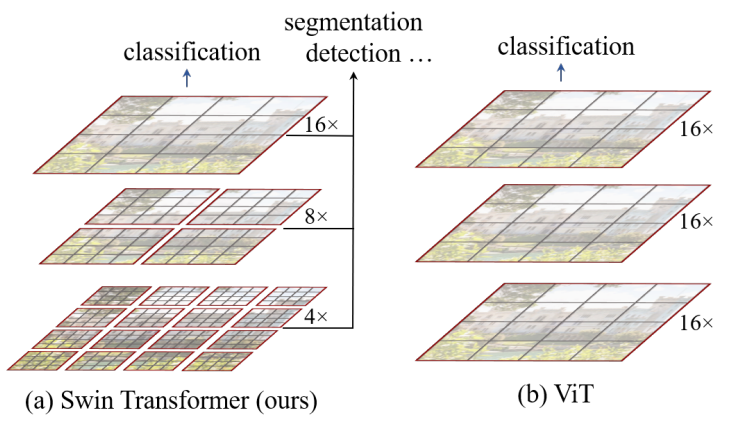
相比于ViT,Swin Transfomer计算复杂度大幅度降低,具有输入图像大小线性计算复杂度。Swin Transformer随着深度加深,逐渐合并图像块来构建层次化Transformer,可以作为通用的视觉骨干网络,应用于图像分类、目标检测和语义分割等任务。
3.1 经典的MLP
MLP模块 由PLA推广而来
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
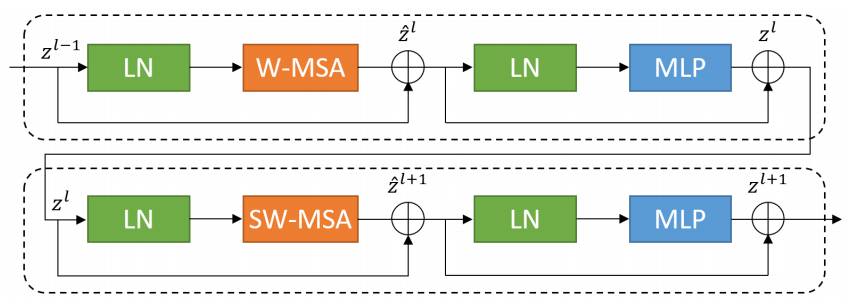
return x3.2 W-MSA & SW-MSA
而本文最精彩的地方,是针对分割后的window,进行重组,加强网络特征提取能力

window分割后,分割的边缘失去了整体信息,网络更多关注window的中心部分,而边缘提供的信息有限,通过重组(一般是在第二个transformer blocks)进行更强的特征提取
W-MSA构建
class WindowAttention(nn.Layer):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
relative_position_bias_table = self.create_parameter(
shape=((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads), default_initializer=nn.initializer.Constant(value=0)) # 2*Wh-1 * 2*Ww-1, nH
self.add_parameter("relative_position_bias_table", relative_position_bias_table)
# get pair-wise relative position index for each token inside the window
coords_h = paddle.arange(self.window_size[0])
coords_w = paddle.arange(self.window_size[1])
coords = paddle.stack(paddle.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = paddle.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten.unsqueeze(-1) - coords_flatten.unsqueeze(1) # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.transpose([1, 2, 0]) # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
self.relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", self.relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(axis=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape([B_, N, 3, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = q @ swapdim(k ,-2, -1)
relative_position_bias = paddle.index_select(self.relative_position_bias_table,
self.relative_position_index.reshape((-1,)),axis=0).reshape((self.window_size[0] * self.window_size[1],self.window_size[0] * self.window_size[1], -1))
relative_position_bias = relative_position_bias.transpose([2, 0, 1]) # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.reshape([B_ // nW, nW, self.num_heads, N, N]) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.reshape([-1, self.num_heads, N, N])
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = swapdim((attn @ v),1, 2).reshape([B_, N, C])
x = self.proj(x)
x = self.proj_drop(x)
return xwindow的划分与合并
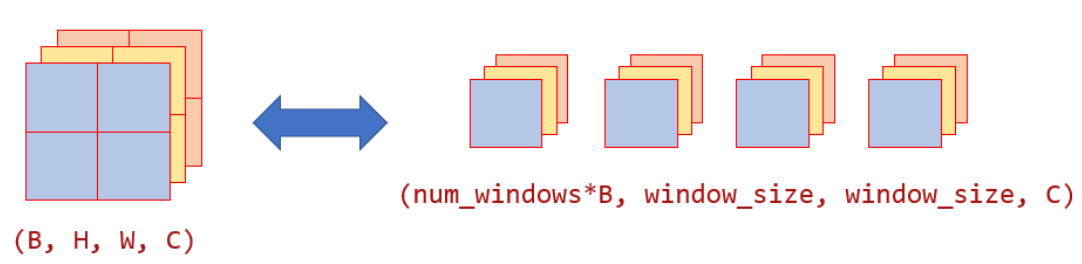
# window_partition是划分,window_reverse是合并
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.reshape([B, H // window_size, window_size, W // window_size, window_size, C])
windows = x.transpose([0, 1, 3, 2, 4, 5]).reshape([-1, window_size, window_size, C])
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.reshape([B, H // window_size, W // window_size, window_size, window_size, -1])
x = x.transpose([0, 1, 3, 2, 4, 5]).reshape([B, H, W, -1])
return x3.3 SwinTransformerBlock
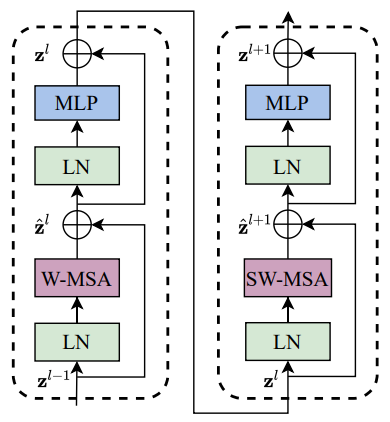
前面不做window shifted,后面做window shifted,这样做的好处可以提取较强的语义特征
class SwinTransformerBlock(nn.Layer):
""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = paddle.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.reshape([-1, self.window_size * self.window_size])
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = masked_fill(attn_mask, attn_mask == 0, float(-100.0))
attn_mask = masked_fill(attn_mask, attn_mask != 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.reshape([B, H, W, C])
# cyclic shift
if self.shift_size > 0:
shifted_x = paddle.roll(x, shifts=(-self.shift_size, -self.shift_size), axis=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.reshape([-1, self.window_size * self.window_size, C]) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.reshape([-1, self.window_size, self.window_size, C])
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = paddle.roll(shifted_x, shifts=(self.shift_size, self.shift_size), axis=(1, 2))
else:
x = shifted_x
x = x.reshape([B, H * W, C])
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchMerging(nn.Layer):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.reshape([B, H, W, C])
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape([B, -1, 4 * C]) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x3.4 将Block和Merging融合
class BasicLayer(nn.Layer):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
# build blocks
self.blocks = nn.LayerList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
class PatchEmbed(nn.Layer):
""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = swapdim(self.proj(x).flatten(2), 1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x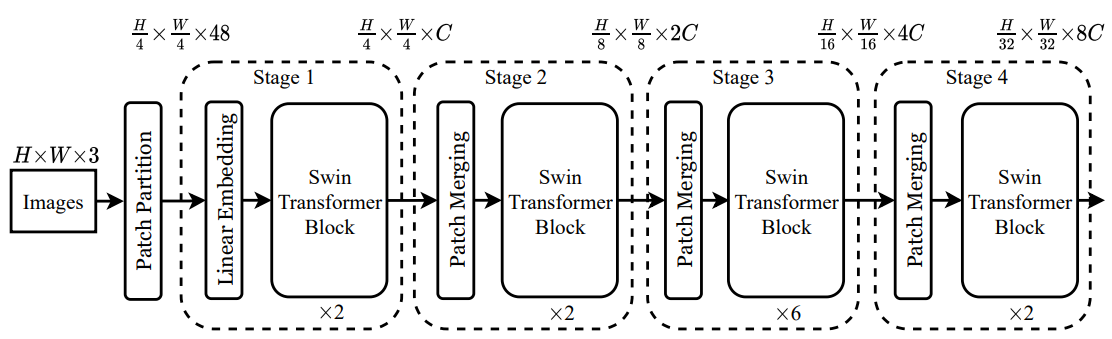
3.5 Backbone的搭建
为什么倒数第二个stage要比其他三个多?
因为stage1,stage2部输入的图像尺寸大,过多增加层数会造成运算增加,而在stage3输入的图像尺寸小,对运算开销小,方便提取高层语义,最后的stage4虽然输入空间维度小,但是Channel过大,会带来不小的计算开销,不如把计算资源分配给stage3,这也是ResNet经典的思想
class SwinTransformer(nn.Layer):
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
**kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = self.create_parameter(shape=(1, num_patches, embed_dim),default_initializer=nn.initializer.Constant(value=0))
self.add_parameter("absolute_pos_embed", self.absolute_pos_embed)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x for x in paddle.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.LayerList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1D(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else Identity()
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(swapdim(x,1, 2)) # B C 1
x = paddle.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x不同backbone搭配方式也不同
- swin tiny:[ 2, 2, 6, 2 ]
- swin samll:[ 2, 2, 18, 2 ]
- swin base: [ 2, 2, 18, 2 ]
- swin large:[ 2, 2, 18, 2 ]
官方发布模型如下
def swin_tiny_window7_224(**kwargs):
model = SwinTransformer(img_size = 224,
embed_dim = 96,
depths = [ 2, 2, 6, 2 ],
num_heads = [ 3, 6, 12, 24 ],
window_size = 7,
drop_path_rate=0.2,
**kwargs)
return model
def swin_small_window7_224(**kwargs):
model = SwinTransformer(img_size = 224,
embed_dim = 96,
depths = [ 2, 2, 18, 2 ],
num_heads = [ 3, 6, 12, 24 ],
window_size = 7,
drop_path_rate=0.3,
**kwargs)
return model
def swin_base_window7_224(**kwargs):
model = SwinTransformer(img_size = 224,
embed_dim = 128,
depths = [ 2, 2, 18, 2 ],
num_heads = [ 4, 8, 16, 32 ],
window_size = 7,
drop_path_rate=0.5,
**kwargs)
return model
def swin_large_window7_224(**kwargs):
model = SwinTransformer(img_size = 224,
embed_dim = 192,
depths = [ 2, 2, 18, 2 ],
num_heads = [ 6, 12, 24, 48 ],
window_size = 7,
**kwargs)
return model
def swin_base_window12_384(**kwargs):
model = SwinTransformer(img_size = 384,
embed_dim = 128,
depths = [ 2, 2, 18, 2 ],
num_heads = [ 4, 8, 16, 32 ],
window_size = 12,
**kwargs)
return model
def swin_large_window12_384(**kwargs):
model = SwinTransformer(img_size = 384,
embed_dim = 192,
depths = [ 2, 2, 18, 2 ],
num_heads = [ 6, 12, 24, 48 ],
window_size = 12,
**kwargs)
return model代码基于Paddle复现,paddle没有的一些torch的api,需要自定义
# torch.masked_fill == masked_fill
# torch.transpose == swapdim
# to_2tuple == 参考timm
# DroupPath == 参考timm
# Identity == 参考torch
import paddle
import paddle.nn as nn
from itertools import repeat
def masked_fill(tensor, mask, value):
cover = paddle.full_like(tensor, value)
out = paddle.where(mask, tensor, cover)
return out
def swapdim(x,num1,num2):
a=list(range(len(x.shape)))
a[num1], a[num2] = a[num2], a[num1]
return x.transpose(a)
def to_2tuple(x):
return tuple(repeat(x, 2))
def drop_path(x, drop_prob = 0., training = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = paddle.to_tensor(keep_prob) + paddle.rand(shape)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class Identity(nn.Layer):
def __init__(self, *args, **kwargs):
super(Identity, self).__init__()
def forward(self, input):
return input参考资料
浅析 Swin Transformer - 飞桨AI Studio
swin transformer理解要点 - 简书 (jianshu.com)