Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
| 标题 | Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation |
|---|---|
| 年份: | 2021 年 5 月 |
| GB/T 7714: | Cao H, Wang Y, Chen J, et al. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation[J]. arXiv preprint arXiv:2105.05537, 2021. |
首个基于纯Transformer的U-Net形的医学图像分割网络,其中利用Swin Transformer构建encoder、bottleneck和decoder,表现SOTA!性能优于TransUnet、Att-UNet等,代码即将开源! 作者单位:慕尼黑工业大学, 复旦大学, 华为(田奇等人)
1 引入
在过去的几年中,卷积神经网络(CNN)在医学图像分析中取得了里程碑式的进展。尤其是,基于U形结构和skip-connections的深度神经网络已广泛应用于各种医学图像任务中。但是,尽管CNN取得了出色的性能,但是由于卷积操作的局限性,它无法很好地学习全局和远程语义信息交互。
在本文中,作者提出了Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer模型。标记化的图像块通过跳跃连接被送到基于Transformer的U形Encoder-Decoder架构中,以进行局部和全局语义特征学习。
具体来说,使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征。并设计了一个symmetric Swin Transformer-based decoder with patch expanding layer来执行上采样操作,以恢复特征图的空间分辨率。在对输入和输出进行4倍的下采样和上采样的情况下,对多器官和心脏分割任务进行的实验表明,基于纯Transformer的U-shaped Encoder-Decoder优于那些全卷积或者Transformer和卷积的组合。
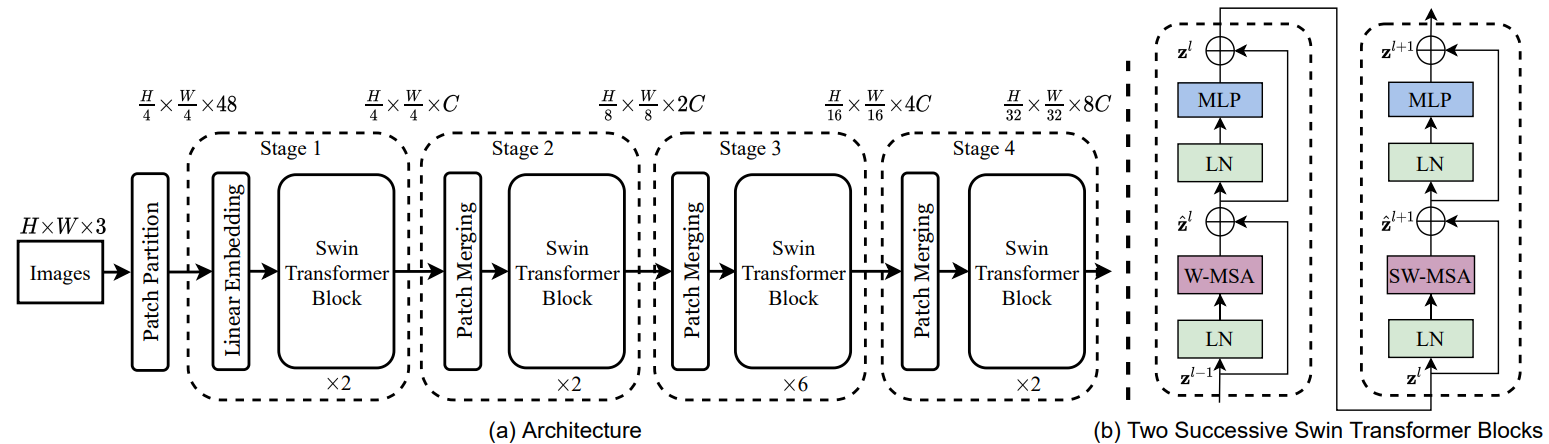
2 Swin-Unet架构
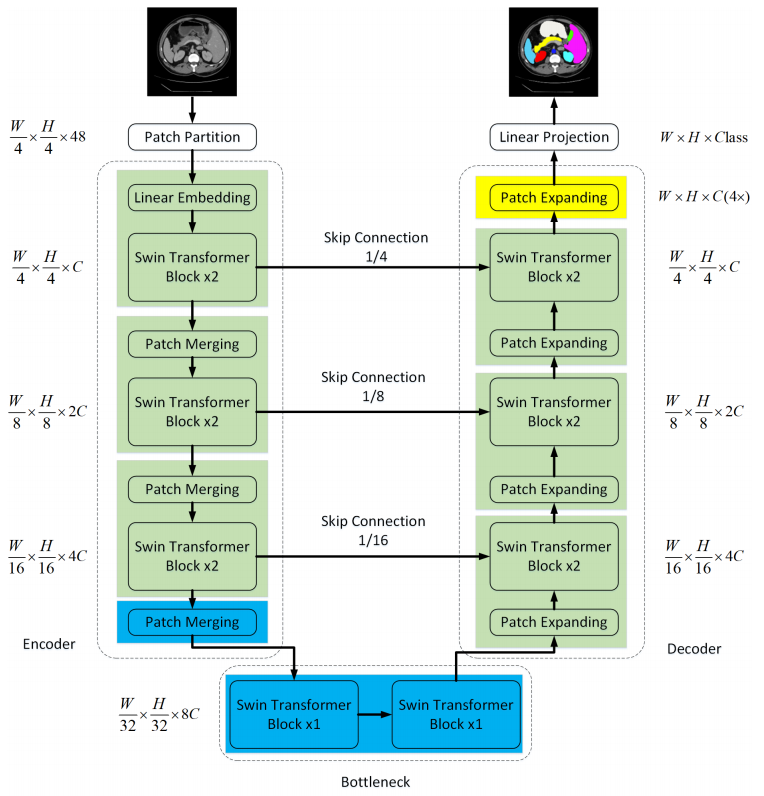
Swin-Unet架构:由Encoder, Bottleneck, Decoder和Skip Connections组成 Encoder, Bottleneck以及Decoder都是基于Swin-Transformer block构造的实现
2.1 Swin Transformer block
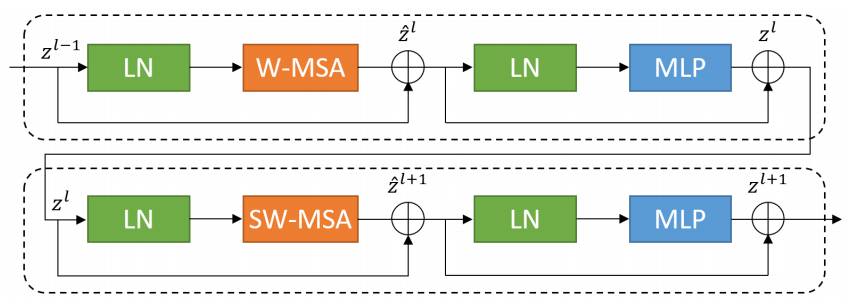
与传统的multi-head self attention(MSA)模块不同,Swin Transformer是基于平移窗口构造的。在图2中,给出了2个连续的Swin Transformer Block。
每个Swin Transformer由LayerNorm(LN)层、multi-head self attention、residual connection和2个具有GELU的MLP组成。
在2个连续的Transformer模块中分别采用了windowbased multi-head self attention(W-MSA)模块和 shifted window-based multi-head self attention (SW-MSA)模块。基于这种窗口划分机制的连续Swin Transformer Block可表示为:
其中,$\hat{z}^l$ 和$z^l$分别表示(SW-MSA)模块和第$l$块的MLP模块的输出
与前面的研究ViT类似,self attention的计算方法如下: $$ \text { Attention }(Q, K, V)=\operatorname{Sof} t M a x\left(\frac{Q K^{T}}{\sqrt{d}}+B\right) V $$
其中,$Q,K,V \in \R^{M^2 \times d}$ 表示query、key和value矩阵。 $M^2$和$d$分别表示窗口中patch的数量和query或key的维度。value来自偏置矩阵$\hat{B} \in \R^{(2M-1) \times (2M+1)}$
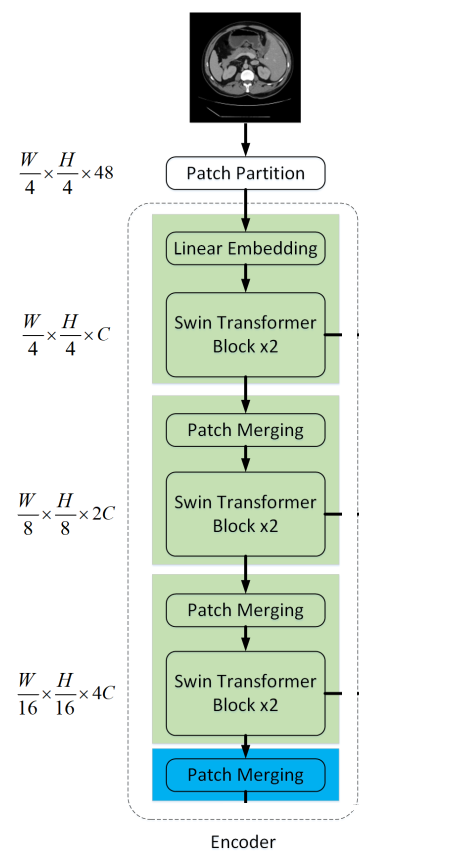
2.2 Encoder
在Encoder中,将分辨率为$\frac{H}{4} \times \frac{W}{4}$的$c$维tokenized inputs输入到连续的2个Swin Transformer块中进行表示学习,特征维度和分辨率保持不变。同时,patch merge layer会减少Token的数量(2×downsampling),将特征维数增加到2×原始维数。此过程将在Encoder中重复3次。
Patch merging layer
输入patch分为4部分,通过Patch merging layer连接在一起。这样的处理会使特征分辨率下降2倍。并且,由于拼接操作的结果是特征维数增加了4倍,因此在拼接的特征上加一个线性层,将特征维数统一为原始维数的2倍。
2.3 Decoder
与Encoder相对应的是基于Swin Transformer block的Symmetric Decoder。为此,与编码器中使用的patch merge层不同,我们在解码器中使用patch expand层对提取的深度特征进行上采样。patch expansion layer将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维数减半。
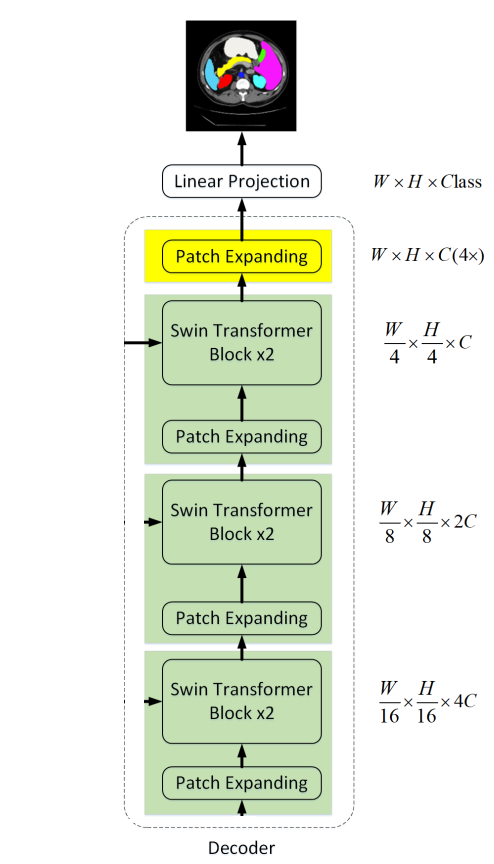
Patch expanding layer
以第1个Patch expanding layer为例,在上采样之前,对输入特征$(\frac{W}{32} \times \frac{H}{32} \times 8C)$加一个线性层,将特征维数增加到原始维数$(\frac{W}{32} \times \frac{H}{32} \times 16C)$的2倍。然后,利用rearrange operation将输入特征的分辨率扩大到输入分辨率的2倍,将特征维数降低到输入维数的1/4,即$(\frac{W}{32} \times \frac{H}{32} \times 16C \rightarrow \frac{W}{16} \times \frac{H}{16} \times 4C)$
Up-Sampling会带来什么影响?
针对Encoder中的patch merge层,作者在Decoder中专门设计了
Patch expanding layer,用于上采样和特征维数增加。为了探索所提出Patch expanding layer的有效性,作者在Synapse数据集上进行了双线性插值、转置卷积和Patch expanding layer的Swin-Unet实验。实验结果表明,本文提出的Swin-Unet结合Patch expanding layer可以获得更好的分割精度。
Table 3. Ablation study on the impact of the up-sampling

2.4 Bottleneck
由于Transformer太深导致收敛比较困难,因此使用2个连续Swin Transformer blocks来构造Bottleneck以学习深度特征表示。在Bottleneck处,特征维度和分辨率保持不变。
2.5 Skip connection
与U-Net类似,Skip connection用于融合来自Encoder的多尺度特征与上采样特征。这里将浅层特征和深层特征连接在一起,以减少降采样带来的空间信息损失。然后是一个线性层,连接特征尺寸保持与上采样特征的尺寸相同。
skip connections数量的影响?
Swin-UNet在$1/4$, $1/8$和$1/16$的降采样尺度上添加了skip connections。通过将skip connections数分别更改为0、1、2和3,实验了不同skip connections数量对模型分割性能的影响。从下表中可以看出,模型的性能随着skip connections数的增加而提高。因此,为了使模型更加鲁棒,本工作中设置skip connections数为3。
Table 4. Ablation study on the impact of the number of skip connection

3 实验
3.1 数据集
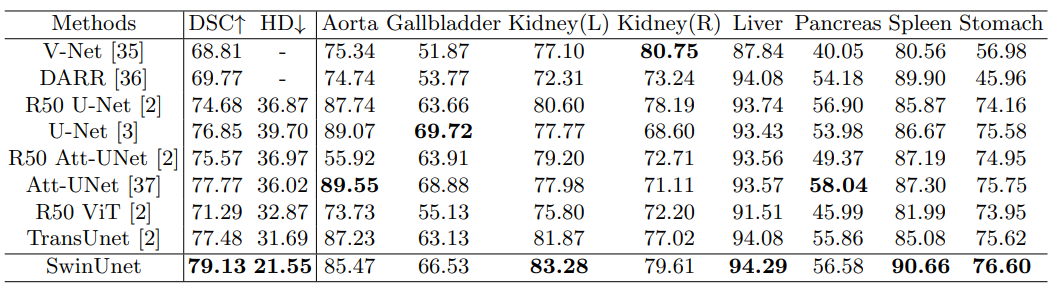
多器官分割数据集(Synapse): 包括30个sample的3779张腹部轴向临床CT图像。18个sample分为训练集,12个sample分为测试集。以平均Dice-Similarity系数(average Dice-Similarity coefficient, DSC)和平均Hausdorff距离(average Hausdorff Distance, HD)作为评价指标,对8个腹部器官(主动脉、胆囊、脾脏、左肾、右肾、肝脏、胰腺、脾脏、胃)进行评价。
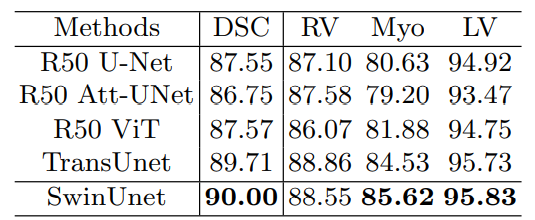
自动心脏诊断挑战数据集(ACDC): ACDC数据集使用MRI扫描仪从不同的患者中收集。对于每个患者的MR图像,左心室(LV)、右心室(RV)和心肌(MYO)被标记。数据集分为70个训练样本、10个验证样本和20个测试样本。在此数据集上仅使用平均差示量分析(DSC)来评估方法。
3.2 Implementation details
- Swin-Unet是基于Python 3.6和Pytorch 1.7.0实现的。
- 对于所有的训练案例,数据增加,如翻转和旋转被用来增加数据多样性。
- 输入图像大小设置为224,patch大小设置为4。
- 在具有32GB显存的Nvidia V100 GPU上训练模型。
- ImageNet上预先训练的权重用于初始化模型参数。
- batch size为24,SGD优化器,weight decay为$1e-4$, momentum为$0.9$。
3.3 实验结果
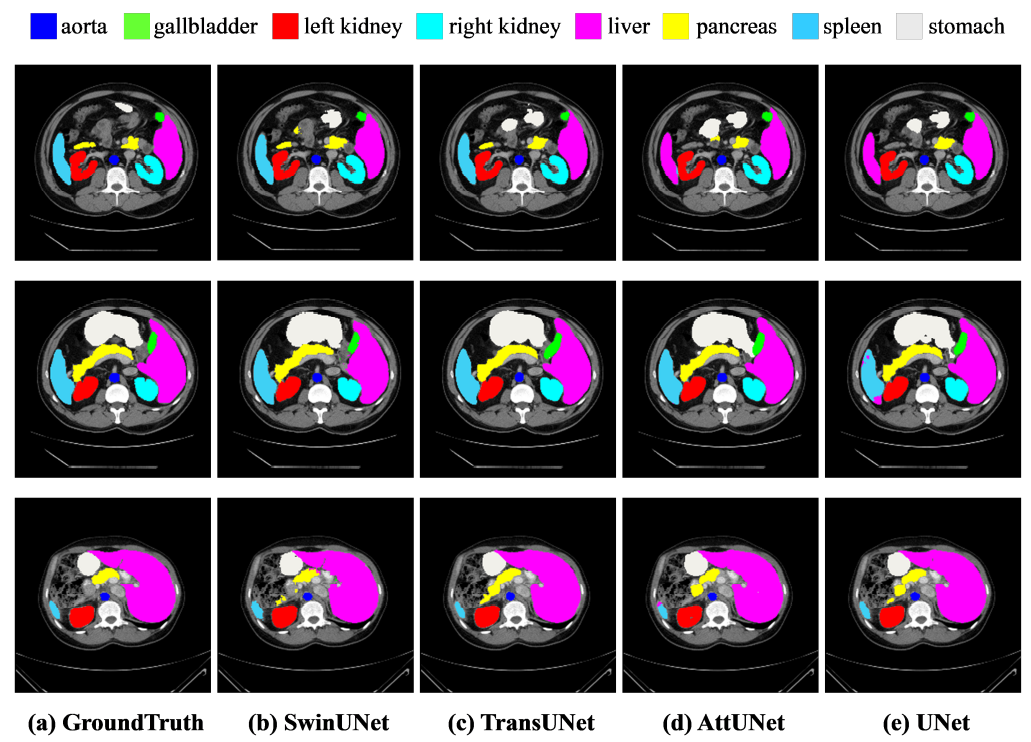
Effect of input size: 以$224\times 224,384 \times 384$作为输入的Swin-Unet测试结果如表5所示。随着输入尺寸从$224\times 224$增加到$384\times 384$,而patch尺寸保持4不变,Transformer的输入token序列会变大,从而提高模型的分割性能。然而,模型的分割精度虽略有提高,但整个网络的计算负荷也有了显著增加。为了保证算法的运行效率,本文的实验以$224\times 224$分辨率尺度作为输入

Effect of model scale:
本文讨论了网络深化对模型绩效的影响,从表6可以看出,模型规模的增加并没有提高模型的性能,反而增加了整个网络的计算代价。考虑到精度和速度的权衡,本文采用基于tiny的模型进行医学图像分割。

参考资料