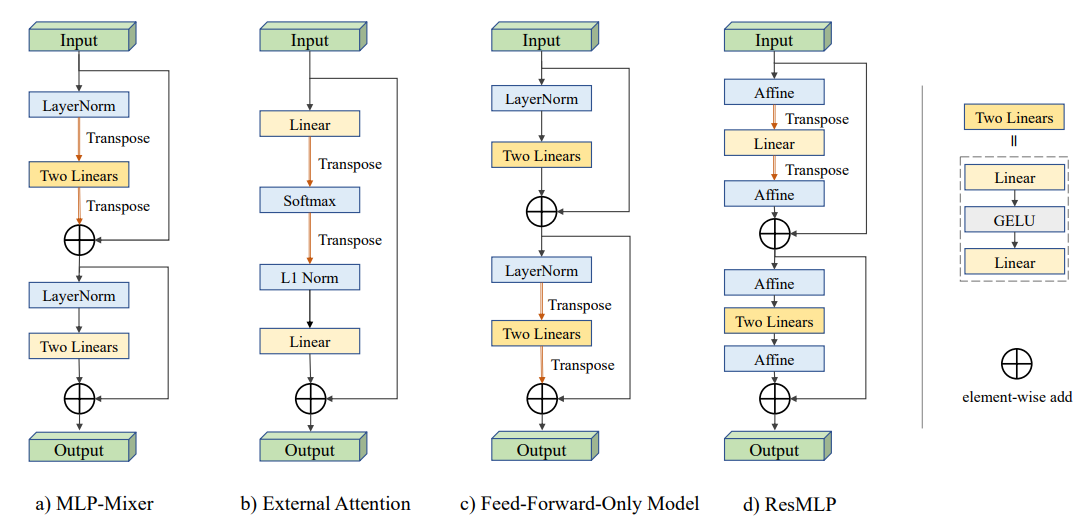
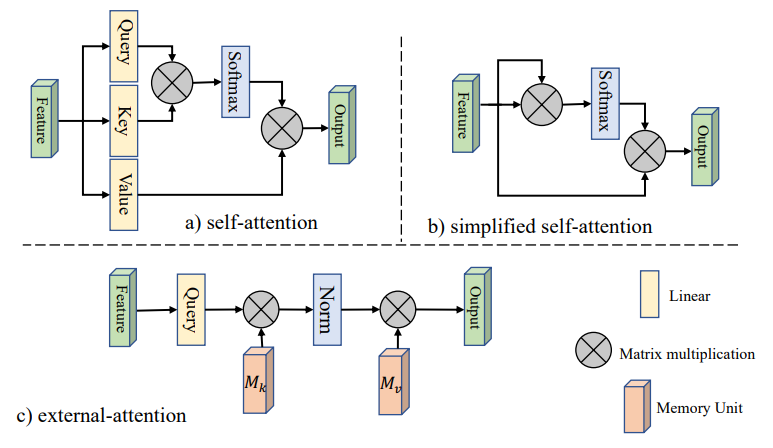
【多层感知机混合器】MLP-Mixer: An all-MLP Architecture for Visio
| 标题 | MLP-Mixer: An all-MLP Architecture for Visio |
|---|---|
| 年份: | 2021 年 5 月 |
| GB/T 7714: | Tolstikhin I, Houlsby N, Kolesnikov A, et al. MLP-Mixer: An all-MLP architecture for vision[J]. arXiv preprint arXiv:2105.01601, 2021. |
| 在这篇文章中,主要证明了卷积和注意力对于良好的性能都是足够的,但它们都不是必要的。提出了MLP-Mixer,一个专门基于多层感知器(MLPs)的体系结构。 |
MLP-Mixer包含两种类型的层:一种是MLPs独立应用于图像patches(即"mixing" per-location features),另一种是MLPs应用于跨patches(即"mixing" spatial information)。
MLP-Mixer在大型数据集或现代正则化方案上进行训练时,可以在图像分类基准上获得有竞争力的分数,其训练前和推理成本可与最先进的模型相媲美。这是一种在概念和技术上都很简单的替代方案,不需要卷积或自注意力机制。
Mixer的架构完全基于多层感知器(MLPs),这些感知器在空间位置或特性通道上重复应用。
Mixer只依赖于
basic matrix multiplication routines,changes to data layout (reshapes and transpositions)和scalar non-linearities
1 方法介绍
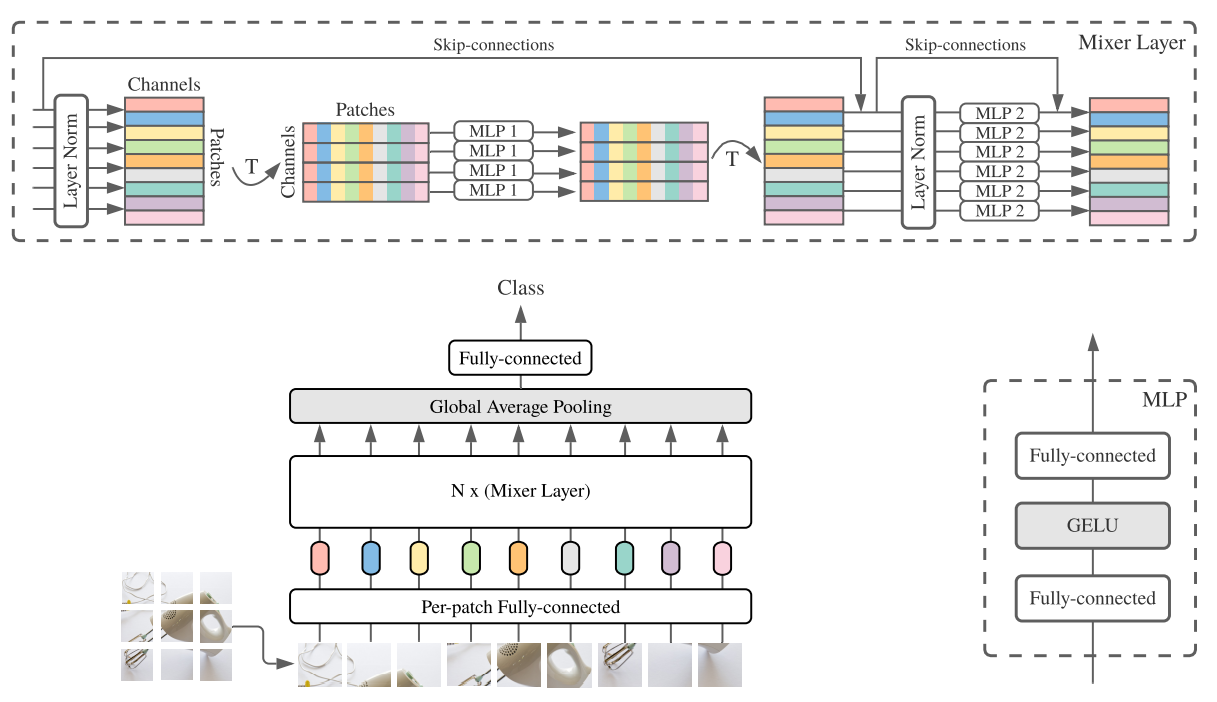
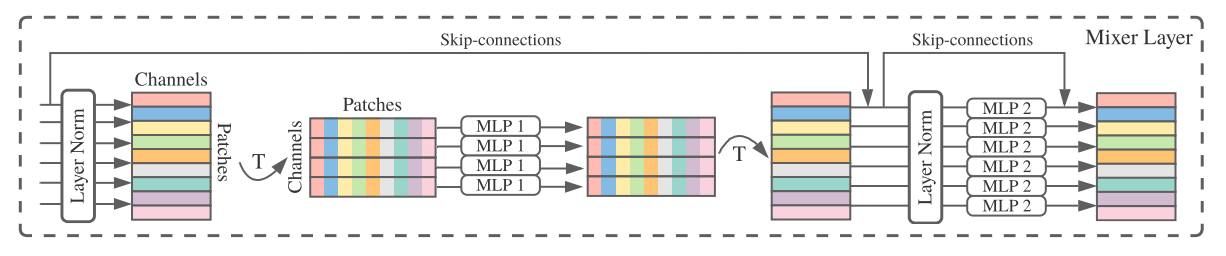
如上图描述了Mixer结构。它接受图像patches经线性投影后的序列(也称为tokens)作为输入,维度为“patches×channels”的表。Mixer使用两种类型的MLP层: channels混合MLP和tokens混合MLP。
Channels混合mlp允许不同通道之间的通信,它们独立地对每个tokens进行操作,并将表中的各个行作为输入。Tokens混合mlp允许不同空间位置(tokens)之间的通信,它们在每个通道上独立操作,将表中的列作为输入。这两种类型的层是交叉的,以支持两个输入维度的交互。
某种程度上说,通道混合类似于1*1的卷积、tokens混合类似于深度可分离卷积。然而,典型的cnn不是特殊情况下的Mixer。此外,卷积比mlp中简单的矩阵乘法更复杂,因为它需要额外地减少矩阵乘法和/或专门的实现。可分离卷积(separable convolutions)中不同通道使用不同卷积核。然而,Mixer每个通道相当于共享相同核。
在大型数据集(约100M张图像)上进行预训练,可以取得与CNN和Transformers的相近的性能,在适中数据集上(约1-10M张图像)结合现有规则化技术,也可以取得相近性能。
1.1 Mixer网络结构
现有深度视觉网络模型,不同层之间混合2种特征:
1). 给定空间位置处的特征; 2). 不同空间位置的特征。
CNN通过N*N的卷积实现2),1*1的卷积实现1);Transformer的self-attention可以同时实现1)和2)。Mixer通过通道混合实现1)、通过tokens混合实现2)。
输入为图像($H*W$)分割后的S个图像块$(S=HW/p^2)$;每个图像块映射为一维(C)的嵌入,总维度为$S*C$的表,然后将这个表输入到N个Mixer层。
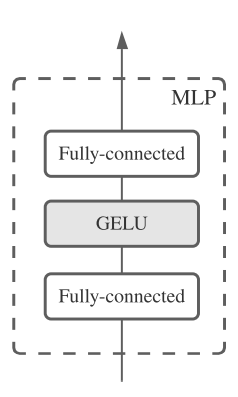
每个MLP层包含2个MLP块。第一个是token-mixing MLP,作用于表的每一列;第二个为channel-mix MLP,作用于表的每一行。每个MLP块包含2个全连接层和一个线性激活。Mixer层可表示如下:
块内与块间的全连接操作与图像像素和块的数量为线性关系,所以总体时间复杂度与CNN相同。
2 实验
2.1 下游任务
使用多个流行的下游任务,如ILSVRC2012 “ImageNet”(1.3M训练样本,1k类别),使用原始验证集标签[13]和清理后的ReaL标签、CIFAR-10/100 (50k样本,10/100类别)、Oxford- IIIT Pets (3.7k样本,36类)和Oxford Flowers-102 (2k示例,102类)。本文还对Visual Task Adaptation benchmark(VTAB-1k)进行了评估,该基准由19个不同的数据集组成,每个数据集有1k个训练示例。
2.2 预训练数据集
遵循标准的迁移学习设置预训练,然后对下游任务进行微调。
在两个公共数据集(ILSVRC2021 ImageNet和Imagenet -21k)上预训练所有模型,其包含了21k类别和14M张图像。
2.3 预训练细节
对于JFT-300M,使用裁剪和随机旋转预处理图像;
对于ImageNet和ImageNet-21k,应用了额外的数据扩充和规则化技术,包括:RandAugment, mixup, dropout, and stochastic depth。
优化器Adam,$β1 = 0.9$,$ β2 = 0.999$,以及$batchsize=4096$,使用weight decay,以及gradient clipping at global norm 1.
2.4 度量
本文对模型的计算成本和质量进行了权衡。对于前者,本文计算了两个指标:
(1) TPU-v3上的总预训练时间,它结合了三个相关因素:每个训练设置的理论FLOPs、相关训练硬件上的计算效率和数据效率。(core-days,每核运行几天)
(2) TPU-v3上的吞吐量以$images/sec/core$为单位。由于不同规模的模型可能受益于不同的批大小,本文设置不同$batch size\{32,64,…,8192\}$,并报告每个模型的最高吞吐量。(每核每妙处理几张图像)
2.5 模型
Big Transfer(BiT):ResNets optimized for transfer learning, pre-trained on ImageNet-21k or JFT-300M.
NFNets:normalizer-free ResNets with several optimizations for ImageNet classification. MPL: EfficientNet-B6-Wide
ALIGN:EfficientNet-L2 image encoder. pre-train image encoder and language encoder on noisy web image text pairs in a contrastive way.
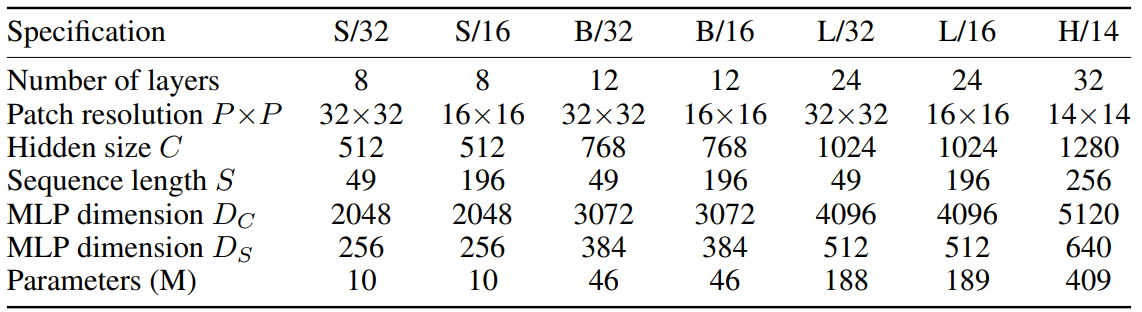
比较了Mixer的各种配置,如表1所示,与最新的、最先进的、cnn和基于注意力的模型(如上所述)。
2.6 实验结果
如下表给出了最大的Mixer模型与最先进模型的比较。“ImNet”和“ReaL”列指的是原始的ImageNet验证标签和清理后的ReaL标签。“Avg.5 “代表所有五个下游任务(ImageNet, CIFAR-10, CIFAR-100, Pets, Flowers)的平均性能。
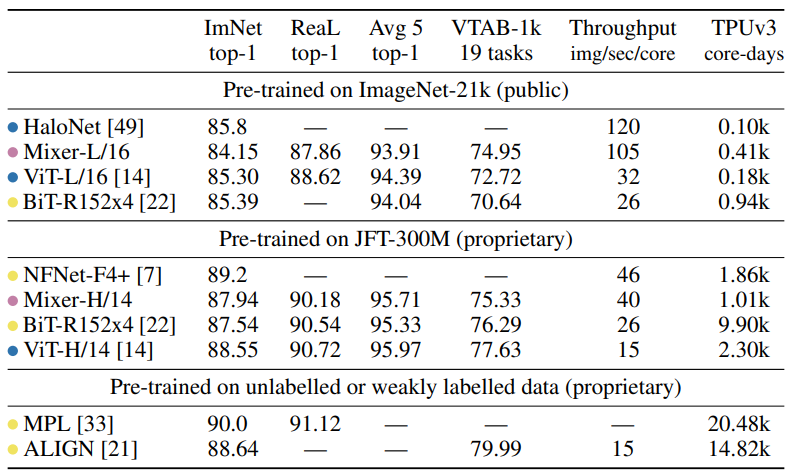
1)当在ImageNet-21k上预训练结合额外的正则化,Mixer实现了一个整体强大的性能(84.15% top-1 on ImageNet)(规则化技术是必要的);
2)当扩大预训练数据集,Mixer性能提升明显,超过了BiT-R152*4;
3)推理速度相比BiT和ViT更快,40:26和40:15;
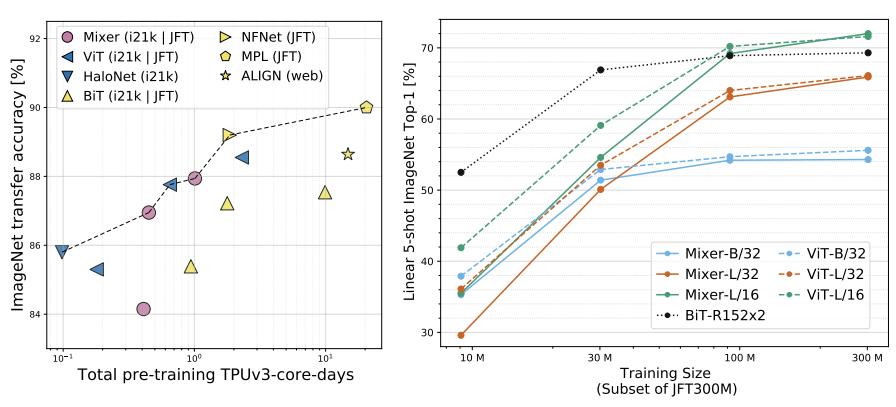
上图(左),展示了在精度-计算量权衡方面Mixer是与传统的神经网络架构具有竞争力的。同时还表明了预训练的总成本和下游精度之间的明显相关性,即使是对于不同得网络模型。
上图(右),展示了随着训练数据量的增加,模型性能的增强。在数据量较小的时候、Mixer过拟合严重,而随着数据量的增大,Mixer增长快于BiT,最终甚至超过了ViT的性能。
2.7 模型大小
通过两种独立的方式缩放模型:
(1) 在预训练时增加模型大小(层数、隐藏维数、MLP宽度)。
(2) 微调时提高输入图像的分辨率。
前者同时影响预训练计算量和测试时间吞吐量,后者只影响吞吐量。
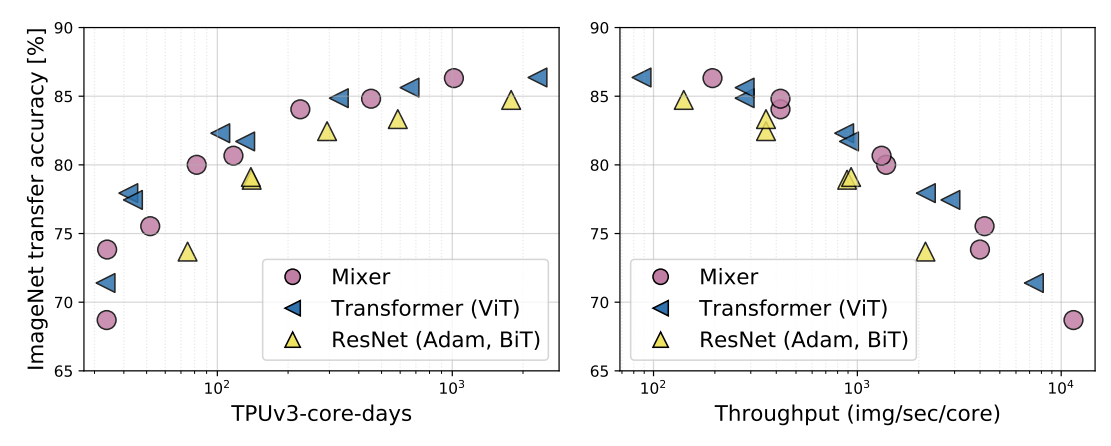
比较了各种配置的Mixer(见表1),与类似规模的ViT模型以及BiT模型。结果如下表和图3所示。
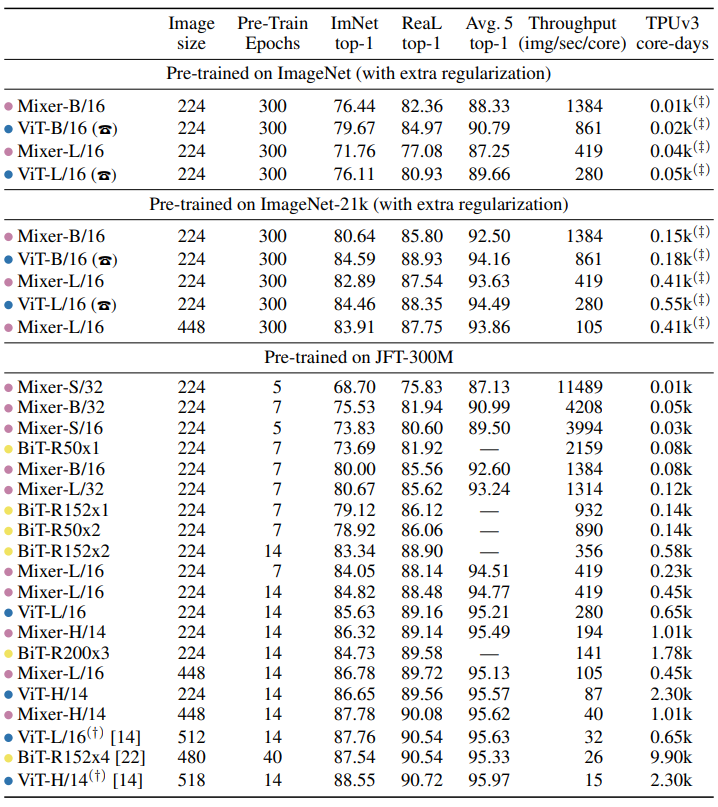
基于ImageNet从随机初始化开始训练, Mixer-B/16实现了一个合理的top-1精度76.44%。这比vitb /16模型低3%。两种模型获得了非常相似的训练损失值。换句话说,Mixer-B/16比ViT-B /16更过拟合。对于Mixer-L/16和ViT-L/16模型,这种差异甚至更加明显。
随着预训练数据集的增长,Mixer的性能稳步提高。值得注意的是,在JFT-300M上训练微调的Mixer-H/14 仅比ViT- h /14在Imagenet上少0.3%,而运行速度快2.2倍。
上图3清楚地表明,尽管Mixer在模型规模较小时略低于最新模型,但随着模型的增大、其竞争力越来越强。
3 可视化
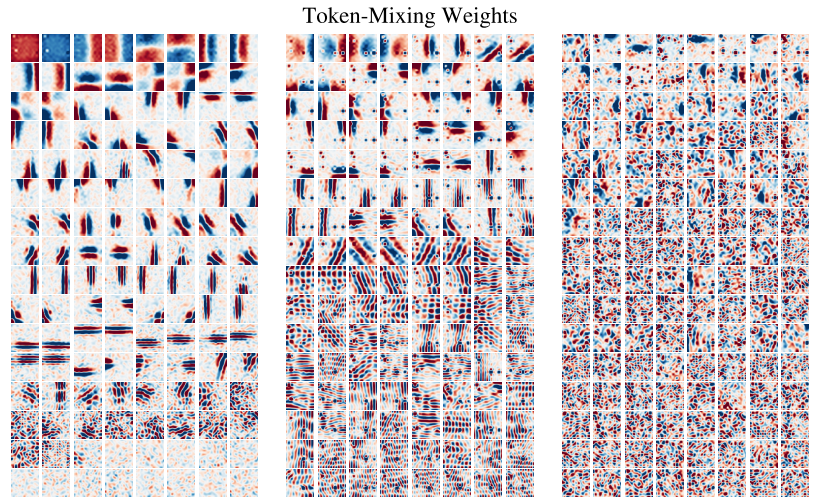
cnn的第一层倾向于学习图像局部区域像素。相反,Mixer允许在token-mixing mlp中进行全局信息交换。
下图显示了在JFT-300M上训练的Mixer前几个token-mixing MLPs的权重。一些学习到的特征作用于整个图像,而其他的作用于更小的区域。第一个token-mixing MLP包含许多局部交互,而第二层和第三层包含更多跨更大区域的混合。较高层似乎没有明显可辨认的结构。与cnn相似,观察到许多低阶特征检测器都以相反相位成对出现(如下图挨着图像、相位相反,且成对出现)。
4 总结
本文描述了一个非常简单的视觉架构。实验表明,在训练和推理所需的准确性和计算资源之间的权衡方面,它与现有的最先进的方法一样好。
本文希望本文的研究结果能激发进一步的研究,超越基于卷积和自我关注的既定模型领域。看看这样的设计是否适用于NLP或其他领域将是特别有趣的。
参考资料
https://arxiv.org/pdf/2105.01601.pdf
无需CNN和Transformer,谷歌新方法MLP-Mixer: An all-MLP Architecture for Vision