Deep Learning for Automatically Detecting Sidewalk Accessibility Problems Using Streetscape Imagery

| 标题 | Deep Learning for Automatically Detecting Sidewalk Accessibility Problems Using Streetscape Imagery |
|---|---|
| 年份: | 2019 年 10 月 |
| GB/T 7714: | [1] Weld G, Jang E, Li A, et al. Deep Learning for Automatically Detecting Sidewalk Accessibility Problems Using Streetscape Imagery[C]. The 21st International ACM SIGACCESS Conference on Computers and Accessibility, 2019: 196–209. |
1 概述
最近的研究已经应用机器学习方法在在线地图图像(例如卫星照片、街景全景图)中自动查找和/或评估行人基础设施。虽然这些方法可以解决人行道的检测,但它们受到两个相互关联的问题的限制: 小的训练集和机器学习模型的选择。本文借助最近发布的人行道数据集(Project Sidewalk dataset),该数据集包括30多万个基于图像的人行道可达性标签,首次检验了深度学习在谷歌街景(GSV)全景图中的人行道自动评估。
具体来说,有两个应用领域:自动验证众包标签automatically validating crowdsourced labels和自动标记人行道可达性automatically labeling sidewalk accessibility issues问题。对于这两个任务,引入并使用一个经过修改的残差神经网络(ResNet)来支持图像和非图像(上下文)特征(例如地理)。提出了性能分析,非图像特征和训练集大小的影响,以及跨城市泛化。实验结果显著改善了以前的自动化方法,在某些情况下,满足或超过人类标记性能。
人行道应该让所有人受益。它们为在城市中移动提供了安全、环保的管道。对于残疾人来说,人行道可以对他们的独立性、生活质量和整体身体活动产生重大影响。虽然像谷歌和苹果地图这样的地图工具已经开始提供以行人为中心的功能,但它们没有包含人行道路线或人行道可达性的信息,这限制了它们的实用性,并对残疾人产生了特别大的影响。关键的问题是数据从何而来、它是如何收集的?
Research Questions:
- R1: 机器学习方法在两个任务(验证和标记)中表现如何?
- R2: 额外的与图像无关的训练特征对表现有什么影响?
- R3: 分类精度如何随着训练数据量的变化而变化?
- R4: 模型在城市环境的效果如何?
贡献:
一种新的深度学习方法,用于自动验证GSV图像中人行道可达性问题的众包标签;
基于GSV图像的人行道问题自动发现与标注的相关方法;
对这些技术如何推广到其他城市进行了初步分析。
2 相关工作
2.1 Residual Neural Networks in Computer Vision
深度学习和神经网络的最新进展显著提高了计算机视觉性能,包括面部识别、场景重建,甚至图像翻译。本方法使用了残差神经网络(ResNets),神经网络的内部网络层之间有捷径连接,允许他们避免一些来过拟合。resnet在许多应用中取得了SOTA结果。
2.2 Computer Vision for Urban Features
计算机视觉界已经研究了各种背景下的城市场景(例如,自动驾驶汽车[,追踪城市变化)。为了训练机器学习系统,需要投入了大量精力来开发标记的街道图像(例如CityScapes数据集)。然而,这些数据(以及用它们训练的模型)主要关注与车辆相关的街道特征,而不是行人。现有的关于检测路缘和路缘坡道的文献主要是通过停车的视角,使用广泛部署在自动驾驶车辆上的摄像头产生的实时数据。虽然一些商业服务应用计算机视觉收集城市数据,但这些服务并没有明确地针对可访问性特征进行识别,同时并不开源的,也没有得到科学的评估,因此使用CV技术来自动检测不同机动性的人的人行道特征仍然没有得到充分的研究。
相关的工作是Sun等的工作,他们使用Siamese训练的全卷积上下文网络(SFC)来识别GSV全景图像中缺失的路缘坡道,该网络评估图像区域周围的上下文。但这项工作受到了一个小的训练数据集的限制(Tohme的1087个标记路口),只关注缺失的路沿坡道,只获得了边际结果(召回率低于30%)。
2.3 Geographic Information Systems
地理信息系统(GIS)的研究人员已经与行人基础设施进行了合作,包括开发一种将人行道数据与街道网格数据结合起来的算法,使用人工标记的卫星图像计算人行道的距离,探索人口普查数据和人行道数据之间的相关性以改善社区健康状况。然而,这项工作的重点是使用现有的人行道特征数据库进行计算,而不是收集关于人行道的新数据。这些现有的数据库要么是由地方政府提供,要么是由研究人员费力地手工标注地图数据创建的。本文研究通过提供新的使用街景图像评估人行道的自动化方法,扩展了之前的工作。
2.4 Uses of Google Streetview in Computer Vision
街景全景图像是主要的图像来源,已被用于半自动跟踪城市绿化,预测房地产价格,训练卷积神经网络(cnn)来检测城市地区随着时间的变化。目前已经有一些初步的工作在使用GSV来识别行人的街道层面的基础设施。例如,Ahmetovic等利用GSV全景图像和卫星图像组合识别条纹(“斑马”)人行横道,召回率为90%,准确率为60%。本文的研究通过使用GSV和深度学习方法来半自动评估与可达性相关的人行道特征:路缘坡道、缺失的路缘坡道、障碍物和路面问题,对之前的工作进行了补充和扩展。
2.5 Hybrid Crowdsourcing and Computer Vision
虽然最近深度学习的发展提高了自动目标检测的性能,但结果并不是很好,并且高度依赖于上下文。因此,研究人员经常将自动化解决方案(快速但嘈杂)与人类工作(缓慢且昂贵,但在某些问题上比机器表现得更好)结合起来,即所谓的混合众包+计算机视觉系统。例如,Hara等人开发了Tohme,它结合了人工标记和计算机视觉,在街景图像中半自动识别路缘坡道和缺失的路缘坡道。他们的混合系统表现得几乎和全手动方法一样好,同时减少了13%的人工劳动时间成本。Ahmetovic等人也探索了混合自动+大众来源标签在人行横道检测中的使用,发现人类能够将查全率从77%提高到93%,准确率从94%提高到97%,但成本和时间显著增加。
3 方法
本文研究了深度学习在街景图像中的两个应用: 自动验证预先标记的GSV全景图像上的人类标签,以及自动标记GSV全景图像来定位和分类人行道可达性问题。对于这两种任务,使用了残差神经网络(ResNet)的深度学习方法。当为每个任务构建单独的模型时,两个网络都在相同的三个输入特征上进行训练:
(i) 从GSV全景图像中截取图像;
(ii) 描述场景中某一点位置的位置特征;
(iii) 地理特征,在城市地理的大背景下描述一个场景的位置。
3.1 模型结构
3.1.1 Residual Neural Networks
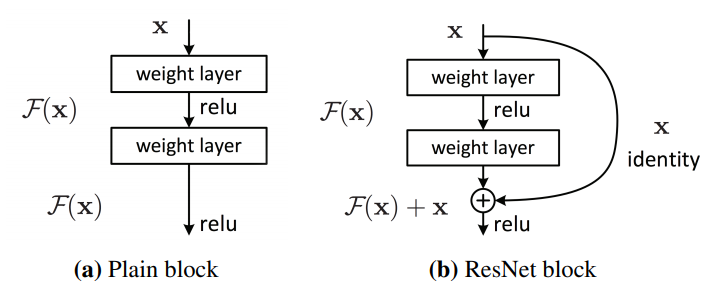
传统的深度神经网络由于过度偏移而层数越多,性能就会下降,而残差网络(ResNets)则允许使用更深的层来提高精度。如图所示,ResNet-18的内层被划分为两层块,其中一个快捷连接将输入的身份添加到块输出中。
3.1.2 Extending Feature Inputs to ResNets
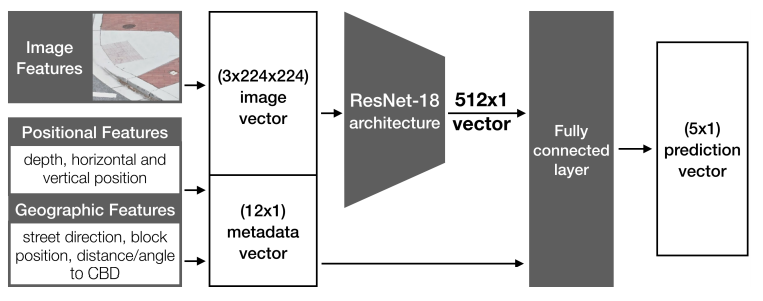
通常,基于resnet的神经网络只将图像作为输入。然而,在本案例中,希望利用额外的上下文知识,例如街景全景图中的作物位置、全景图在城市中的地理位置,或街道上全景图的相对位置(即与十字路口的距离)。为了将图像和非图像输入特征合并到ResNet模型中,执行一个两阶段的输入过程。首先,输入一个224x224x3图像向量通过一系列ResNet的卷积获得512x1的本征向量,加入中间ResNet层作为降维的方法。然后添加上下文特征向量(12x1)到这个512x1的本征向量,最后生成大小为524x1向量,再输入到全连接层,输出5x1的预测向量。这里,行对应于这五个类中的每一个的预测置信度。为了确定最终的预测,只需计算预测向量的argmax。
3.1.3 Transfer Learning Using ImageNet
最后,为了提高性能,使用迁移学习,使用在ImageNet图像语料库上的训练前学到的权重来初始化ResNet模型。在实验中,发现迁移学习的加入显著改善了的测试结果,通过将路缘坡道的自动验证提高到60%以上。
3.2 输入特征
有三种类型的输入特征,捕捉GSV全景图中特定点的外观和地理结构:
- Image Features: 从的SV全景图中裁剪出来的
224x224像素RGB图像,编码场景中点周围的视觉外观。该图像根据其与GSV摄像机的距离自动成比例,然后将其降采样到224x224x3,然后输入到神经网络。- Positional Features: 该点在场景中的位置编码,为一个
7x1向量,包括:
- 由LiDAR计算的该点到GSV车辆的距离(即该点在场景中的
深度位置);- 该点与街道轴线之间夹角的正余弦值(即该点在场景中的
水平位置);- 点与地平线之间的夹角的正弦和余弦(即点在场景中的
垂直位置)。- Geographic Features: 一个
5x1的向量,包括:
- 街道轴线相对于正北的
正弦和余弦;- 全景图到市中心的
距离和方位;- 全景图在街道段内的
绝对位置及相对位置(即距离最近的十字路口的距离)
3.2.1 Extracting Image Crops from Point Labels
由于提供的标签是全景图上的x、y点标签(而不是边界框),所以需要一种方法来自动调整这些点周围的作物的大小。难点在于在不同的距离(例如,光学角度)上补偿不同的视尺寸的物体。例如1米宽、5米远的路缘坡道会比50米远的相同的路缘坡道看起来更大。为了整合光学透视并相应地自动调整作物的大小,使用GSV depth 数据,大小(像素)= 15∗距离+ 200。
3.3 数据
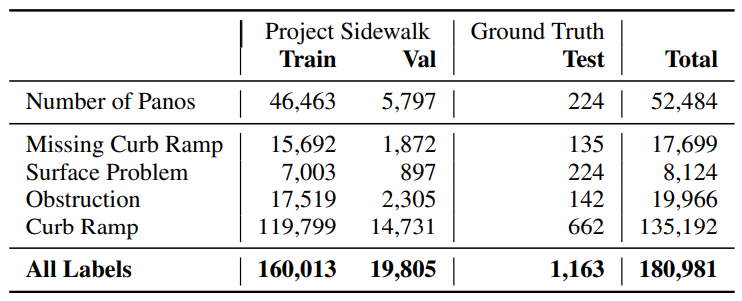
使用Project Sidewalk数据集进行训练和验证,该数据集包含205385个基于图像的人行道可达性标签,数据来自华盛顿州58034个GSV全景照片。按照80/10/10分割将这些全景图和它们对应的标签随机划分为训练集、验证集和测试集。
对于测试,通过标记测试数据集的子集(5774个全景中的224个)手动创建一个ground-truth数据集。生成这个子集是为了确保每种标签类型至少有100个示例。在标注方面,全面标注了每个全景图中所有可见的可及性问题。每个全景图需要大约4-5分钟的标签完全。任何完全模糊或太遥远而无法确定的可达性问题都没有被标注。
3.4 Task
本文研究了ResNet模型在街景图像中的两个应用: 自动验证众包标签和自动标记人行道可达性问题。将提供的手动人行道可访问性标签以图像裁剪加上位置和地理特征的形式输入到ResNet模型中。输入了完整的GSV全景图进行标注,模型自动查找和分类人行道可达性问题。同样,低可信度的预测可以通过众包进行人工验。
3.4.1 验证
对于验证,首先提取每个人提供的点标签周围的作物以及相应的位置和地理特征。然后将这些特征输入到本文的模型中进行分类,该模型输出一个5x1的置信值向量,分别对应四种标签类型: 路堑坡道、缺失路堑坡道、障碍物和表面问题,再加上一个用于预测没有标签的空置信值。在Ground Truth数据集上计算模型的查全率来评价模型的性能。
Center Crop Generation ,使用上面描述的技术生成图像裁剪:以每个x,y点标签为中心提取一个自动大小的目标。为了预测可访问性问题的消除,通过对未标记(缺乏感兴趣的结构)x,y全景坐标进行均匀随机抽样来生成一组零目标。如果随机抽样的空作物与包含标签的目标重叠,则丢弃它。零目标只在地平线和全景图底部上方1600像素之间采样,这样就去掉了多余的天空和道路图像。这些范围是由用于培训的所有众包标签的最大y轴范围决定的
3.4.2 标记
验证侧重于验证手动标记的全景图,而自动标记侧重于自动发现和分类GSV全景图中的人行道可达性问题。使用标准的滑动窗口方法,它将全景图分解成小的、重叠的目标,然后将这些目标传递到神经网络中进行分类。
神经网络为每一种目标输出一个5x1的预测向量,通过argmax来计算一个单一的预测类,以找到最具可信度的类。预测类为null的目标将被忽略。剩下的预测用非最大抑制聚类(non-maximum suppression)。将给定标签类型的重叠预测分组在一起,保留置信度最高的预测,而抑制较弱的预测。本文使用的重叠阈值为150像素,通过定性评价确定。然后,应用剔除步骤,去除低置信。可调节的超参数,γ(较大的值)γ(导致更少的假阳性),提高精度,而较小的γ导致更少的假阴性,提高召回率。剔除后,模型输出最终的预测标签。
为了评估性能,将模型预测的标签与提供的ground truth数据集的全景图片上的标签进行比较。为了确定哪些预测是正确的,哪些是错误的,每个ground truth数据集的标签都被分配一个(宽度,高度)与其在全景图中的深度成比例,使用与生产作物相同的算法。如果预测标签和ground truth标签之间的距离是ground truth 目标的max(width, height),则预测标签被标记为正确。每当一个预测被标记为正确时,相应的ground truth标签就被标记为已解释,其他预测就不能被标记为正确。这可以防止重复计算正确的预测:正确预测的数量不能超过ground truth标签的数量。
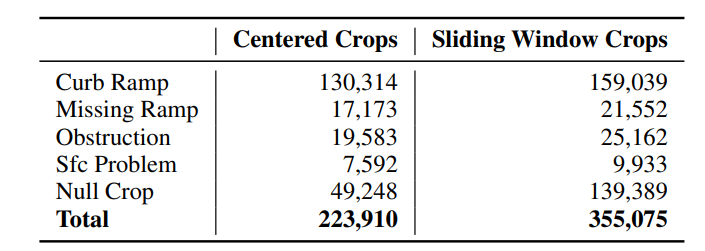
Sliding Window Crop Generation ,对于标注任务,模型被训练在使用滑动窗口产生的目标上(表2)。训练集中的每个全景被分割成一个规则的重叠目标网格,中心间隔一个步长距离。网格中的任何包含数据集中位于其中心$\frac{stride}{\sqrt{2}}$像素内的标签的裁剪都被相应地标记为,任何包含多个不同类型标签的作物都会被忽略。滑动窗口目标总是重叠的,所以来自数据集的标记项经常出现在多个作物中。因此,滑动窗口的目标集比使用中心裁剪技术训练验证模型所创建的目标集要大。没有标记人行道问题的作物被分配一个null的标签。由于来自任何全景图的滑动窗口作物的绝大多数都是空的,为了防止数据集不平衡,每个全景图除了三个均匀随机采样的空值外,其余的都被丢弃。
4 实验与结果

4.1 R1: 评估自动验证性能
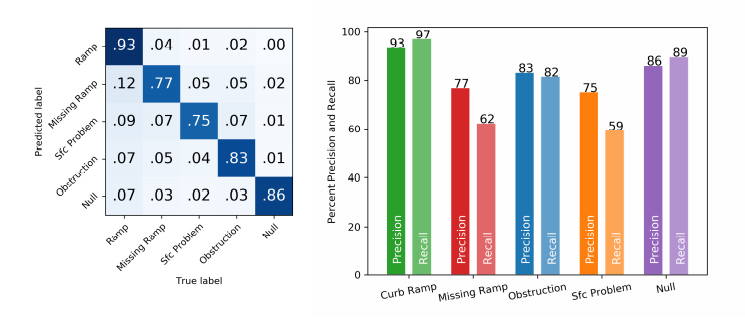
在自动标注任务中,整体表现下降到47.0%的准确率和41.2%的查全率(当γ=4)。路堑坡道表现最好,准确率和查全率分别为89.8%和48.9%,而缺失路堑坡道表现较差,准确率为25.5%,查全率为31.0%。
4.2 R1:评估自动标记性能
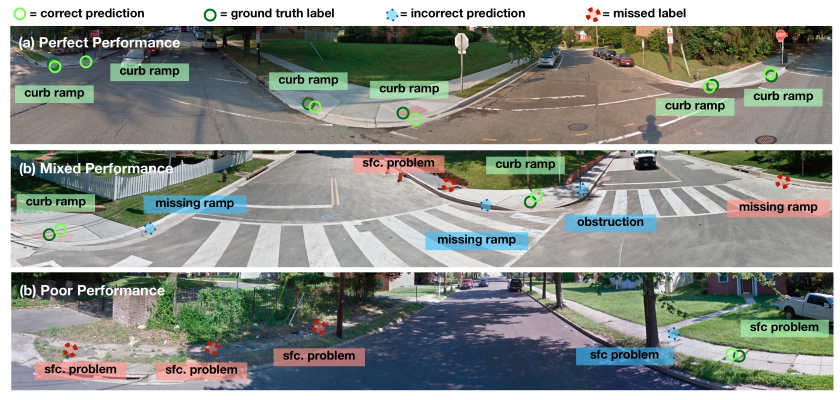
- 标记任务的示例结果,显示了预测和地面真相标签。(a)表现完美,检测到所有功能。(b)表现一般。斜坡被准确地探测到,但是缺失的斜坡被遗漏了,就像表面问题一样,预测了几个假阳性。(c)表现不佳。发现了一个表面问题,但漏掉了很长一段损坏的人行道,添加了一个伪表面问题。
- 确回曲线在标注任务上的表现
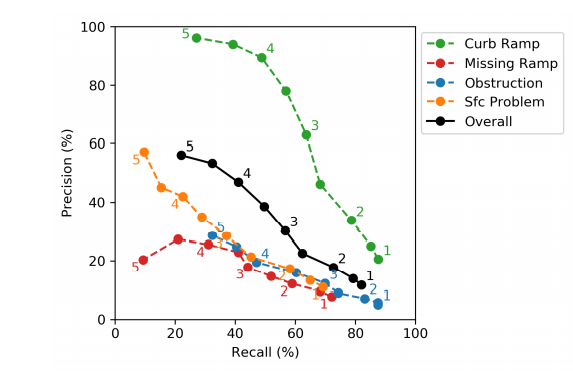
-
与手工标注和与之前工作中自动贴标的比较
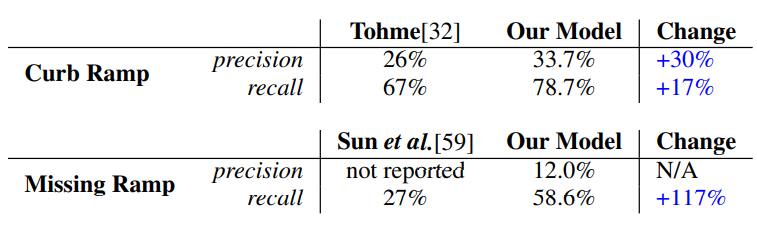
与手工标注和与之前工作中自动贴标的比较
4.3 R2:上下文输入特征对性能的影响
修改后的ResNet-18架构融合了非图像特征,如场景中作物的位置(即位置特征)以及全景图在城市中的相对地理位置(即地理特征)。实验了三种不同的输入特征组合:图像、图像+位置和所有特征(图像+位置+地理)。在实验中,模型在中心作物训练集上进行训练,并在地面真实数据集上进行评估。
随着位置特征和地理特征的增加,精确度和回忆率的变化。底色表示从基线开始性能的增加或减少(仅限图像特征)。
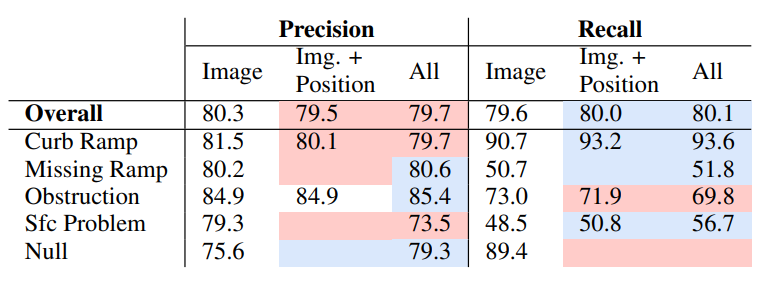
4.4 R3:训练集大小设置
-
整体性能和特征类型随着训练集的大小增加。
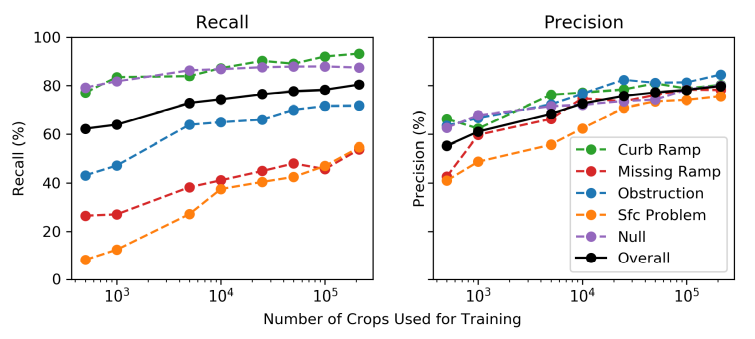
训练集大小对比
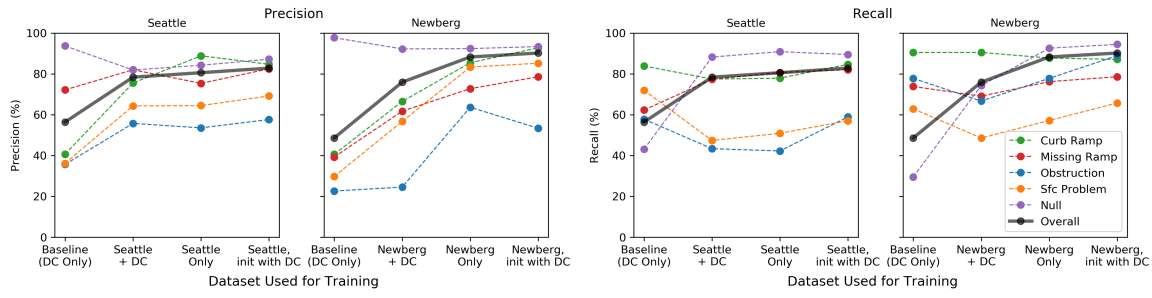
4.5 R4:Cross-city通用性实验
使用了来自两个新的Project Sidewalk deployment cities的最新开放数据集:华盛顿州西雅图(75万居民)和纽约州纽伯格(有2.2万居民)。
使用四种不同的方法进行训练,并在Seattle和Newberg上进行测试
进行四个跨城市的实验——都使用自动验证模型,但在训练集组成上有所不同,每个模型都在各自城市(西雅图或纽伯格)的测试集上进行了评估。这四种模型包括:
- Baseline Model: trained on DC only.
- DC + New City Model: trained on both DC and the other city (either Seattle or Newberg).
- New City-only Model: trained on only Seattle or only Newberg without any DC data.
- (Best performing) New City-only Model Initialized with DC: same as New City-only, but initialized with the weights from the DC model (‘pre-trained’) before training on the new city data.
5 结论
本文的首要目标是利用机器学习开发快速准确的人行道评估方法,以帮助市政府和公民改变跟踪、维护和使用行人基础设施的方式。本文演示了将深度学习方法用于街道景观图像中的自动验证和自动标记人行道。改进的ResNet模型显著改善了以前的自动化系统的性能,在某些情况下,达到或超过人类标记的性能。