LaneAF: Robust Multi-Lane Detection with Affinity Fields
| 标题 | LaneAF: Robust Multi-Lane Detection with Affinity Fields |
|---|---|
| 年份: | 2021 年 3 月 |
| GB/T 7714: | Abualsaud H, Liu S, Lu D, et al. LaneAF: Robust Multi-Lane Detection with Affinity Fields[J]. arXiv preprint arXiv:2103.12040, 2021. |
具有亲和力域的鲁棒多车道检测
1 摘要
本研究提出了一种涉及二值分割掩码和像素级亲和域预测的车道检测方法。可以在后处理步骤中使用这些亲和字段以及二进制掩码将车道像素水平和垂直聚类到相应的车道实例中。这种聚类是通过一个简单的逐行解码过程实现,需要的算力很小;这种方法允许LaneAF在不假设固定或最大车道数的情况下检测可变数量的车道。此外,这种聚类与以前的视觉聚类方法相比更具可解释性,可以通过分析来识别和纠正错误。在常用车道检测数据集上获得的结果表明,该模型能够有效、稳健地检测和聚类车道。本文提出的方法在Tusimple测试上与SOTA表现相同,并在CULane数据集上获得了SOTA。
2 引言
车道检测是自动感知标记车道形状和位置的过程,是自动驾驶系统的重要组成部分,直接影响车辆的引导和转向,同时也帮助道路上众多agent之间的交互。随着道路上的司机数量的增加,自动驾驶系统已经在汽车和科技行业以及学术界得到了相当大的关注。根据公路安全保险研究所(IIHS)的数据,仅在美国,2018年的车祸就夺走了36560人的生命,这凸显了任何有助于预防车祸的技术的重要性。
由于道路通常有不同类型的车道线(纯白、破白、纯黄等),每一种车道线都有特定的含义,车辆可以与它们交互,自动车道检测系统也可以在路况变化时帮助提醒司机。此外,还有几个因素使车道检测成为一项具有挑战性的任务。首先,世界上有各种各样的道路基础设施;此外,车道检测系统必须能够识别车道结束、合并和分流的情况;最后,车道检测系统必须具有识别磨损或不清楚的车道标志的能力。车道的精确检测也使周围车辆的轨迹预测更加鲁棒。
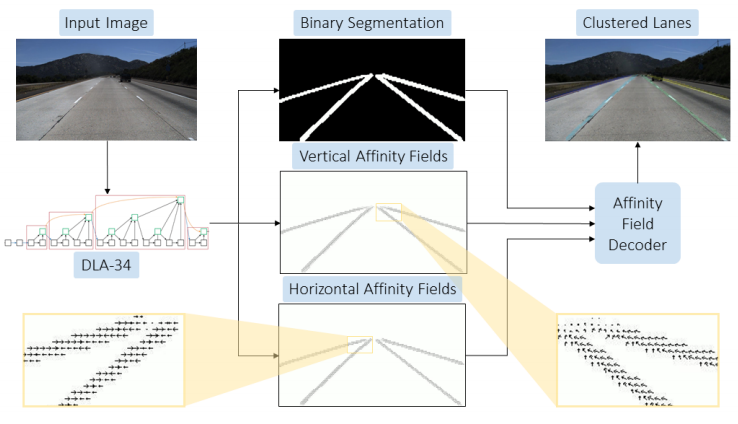
本文方法中使用了二进制分类来检测车道,但这种类型分类产生一个单通道输出,导致不能识别单独的车道实体。为了分离不同的车道,提出了一种基于亲和域的新聚类方案(见图1)。亲和域最初被用于多人二维姿态估计,它由单位向量,编码位置和方向组成。本文定义了两种类型的亲和场——水平亲和场(HAF)和垂直亲和场(VAF)。这些关联字段使唯一的lane实例能够被识别和分段。由于这些亲和域会出现在任何有前景通道像素的地方,因此它们不会绑定到预定数量的通道。因此,该模型与道路上的车道数量无关。
本文的主要贡献如下:
- 展示了使用卷积神经网络(CNN)为骨干网,本质上聚合和细化多尺度特征,与之前提出的其他定制架构和车道检测损失相比,可以获得更好的性能。
- 优于其他架构和之前提出的车道检测损失。
- 详细介绍了用于车道实例分割的预测二值分割掩码和亲和域的训练模型的过程和损失。
- 引入了有效的方法来生成和解码此类关联字段到未知数量的集群通道实例中。
3 研究方法
提出的方法包括一个前馈CNN,它被训练来预测二进制车道分割掩码和逐像素亲和域。该模型被训练来预测两个亲和场,分别称之为水平亲和场(HAF)和垂直亲和场(VAF)。亲和性场就是向量场,它将图像平面上的任何2D位置映射为2D中的单位向量。
VAF中的单位向量对其上方的下一组车道像素所在的方向进行编码;HAF中的单位向量指向当前行的车道中心。这两个亲和域与预测的二值分割,然后可以用于聚类前景像素通道作为后处理步骤。
3.1 Network Backbone
近期车道检测方法利用了各种主干架构;但其中最流行的通常是ResNet系列架构、ENet和ERFNet。本文中提出了DLA-34骨干网络。
DLA模型族利用了深层聚合,将语义和空间融合统一起来,以便更好地进行定位和语义解释。特别是这种架构扩展了紧密连接的网络,并具有层次化和迭代跳过连接的金字塔网络的特征,提高了表达力,细化了分辨率。两种聚合:迭代深度聚合(IDA)和层次深度聚合(HDA)。IDA专注于融合分辨率和尺度,而HDA专注于合并所有模块和通道的特性。这些架构还包含了可变形的卷积操作,可以根据其输入对空间采样网格进行卷积调整。
3.2 Affinity Fields
除了二值车道分割掩码外,本文的模型还被训练来预测水平和垂直亲和场(HAFs和VAFs)。对于任何给定的图像,HAF和VAF可以被认为是向量$\vec{H}(·,·)$和$\vec{V}(·,·)$,为图像中的每个$(x, y)$位置分配一个单位向量。HAF能够水平地聚集车道像素,而VAF能够垂直地聚集车道像素。利用预测的亲和域和二值掩码,通过简单的逐行解码过程从下到上实现聚类通道像素。

Creating HAFs and VAFs: 如算法1所示,使用Ground Truth分割掩模动态创建亲和字段,从下到上一行一行地进行。对于图像中的任意y行,使用地面真向量场映射$\vec{H_g}t(·,·)$计算每个车道线点$(x^l_i,y)$的HAF向量,如下所示
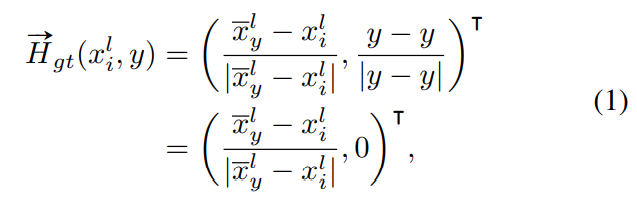
其中$\bar{x}^l_y$是y行中属于l车道的所有点的x坐标的平均值,这个过程如图2a所示,其中绿色和蓝色的像素分别表示属于l车道线和l+1车道线的点。
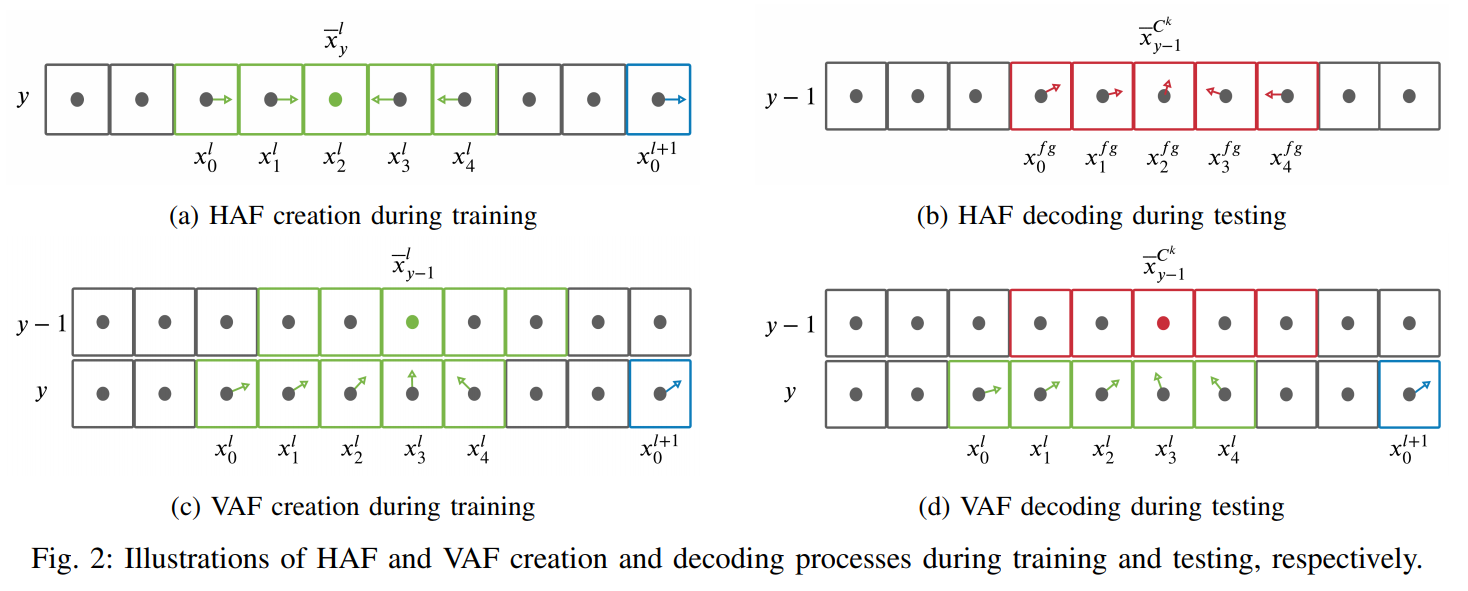
类似地,计算每个车道线点$(x^l_i,y)$的VAF向量在y行使用地面真向量场映射$\vec{V_g}t(·,·)$如下所示
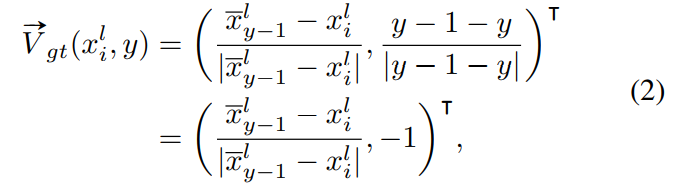
其中,$\bar{x}^l_{y-1}$是$y-1$行中属于l车道线的所有点的x坐标的平均值。这一过程如图2c所示,其中绿色像素表示属于车道l的点。注意,与HAF不同,VAF中的单位向量指向前一行车道的
平均位置。
Decoding HAFs and VAFs: 在训练模型预测上述HAFs和VAFs后,在测试过程中进行一种解码程序,将前景像素聚类为车道。该程序在算法2中给出,从下到上逐行操作。

设$\vec{H}_{pred}(·, ·)$是预测的HAF对应的向量场,第y−1行前景像素首先按照以下规则分配簇:
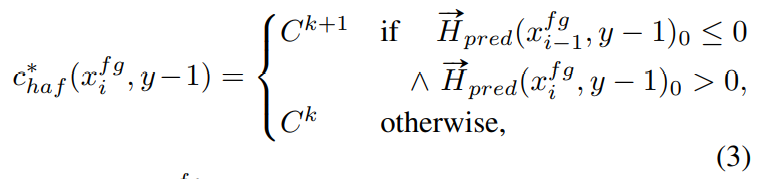
其中,$c^*_{ haf} (x^{fg}_i, y-1)$表示前景像素$(x^{fg}_i, y-1)$的最优聚类分配;$C^k$和$C^{k+1}$分别表示用k和k+1索引的两个不同簇。这种分配如图2b所示,其中红色的像素被分配为相同的簇。
使用VAF对应的向量场$\vec{V}_{pred}(·, ·)$将这些水平簇分配给l索引的现有车道,如下所示:

在图2d中说明了这个过程,其中红色的簇被分配给绿色的现有车道。通过从底部到顶部逐行重复上述步骤,能够将每个前景像素分配到它们各自的车道上
3.3 Losses
为了训练所提出的模型,在每个预测头使用一个单独的损失。对于本文的二值分割分支,使用加权二值交叉熵损失,一种不平衡二值分割任务的标准损失。模型生成的原始logit首先通过sigmoid激活进行规范化。然后将损失计算为

其中$t_i$是像素I的目标值,$o_i$是sigmoid输出。由于这是一个不平衡的分割任务,权重$w = 9.6$用于增加前景像素的惩罚。为了进一步解释不平衡的数据集,在分割分支中使用了联合损失的额外交集
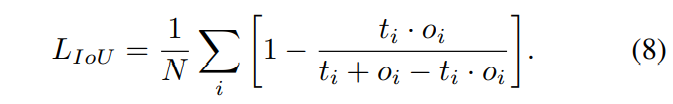
对于模型的亲和场分支,简单的L1回归损失仅应用于垂直和水平亲和场的前景位置:
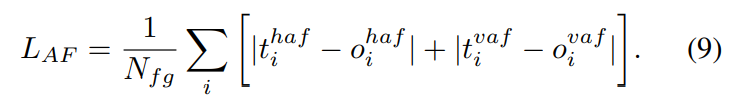
适用于该模型的总损失是单个损失的简单总和:
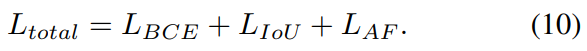
4 实验
4.1 数据集
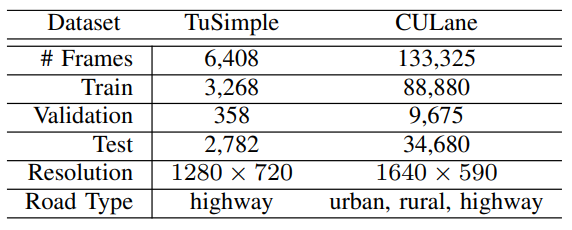
为了训练和测试本文提出的方法,使用流行的Tusimple和CULane数据集。TuSimple包含了3,626个带注释的训练视频剪辑和2,782个用于测试的剪辑。它的特点是,在各种日间照明和交通条件下,天气状况良好,可使用多达五车道的高速公路。CULane包含了更多的数据,有88880个带注释的训练视频剪辑和34680个用于测试的剪辑。该数据集还将测试图像分为9类,并包含更复杂的场景,包括具有挑战性光照条件的图像。两个数据集的摘要汇编在表I中。
4.2 实验配置
主干架构(DLA-34)是一个全卷积网络,它不保留原始的分辨率,而是将输出缩小到原来的4倍;因此,在运行时动态地将输入图像缩放为$640x352$,并将ground truth affinity field和segmentation masks重塑为$160x88$,这是输入大小的四分之一。这样做的另一个好处是使解码过程更快,因为现在只处理原始行的四分之一。在训练中,还使用了随机旋转、作物、缩放和水平翻转。
对DLA-34骨干使用ImageNet预先训练的权重,并相应地规范化输入。最后,在所有实验中使用Adam优化器作为本文的求解器。其他训练参数如下所示:
- Epochs = 60
- Batch size = 2
- Learning rate = 1e − 4
- Weight decay = 1e − 3
评价标准
使用过去文献中使用的同样的评估指标,对本文的方法和以前的工作进行了比较。包括TuSimple数据集的官方度量(accuracy)、假阳性(FP)率和假阴性(FN)率。计算TuSimple精度为:
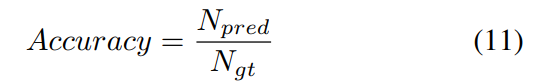
其中$N_{pred}$为已被正确预测的车道点的数量,$N_{gt}$为ground-truth车道点的数量。此外F1度量,它基于union (IoU)的交集,是CULane的唯一度量。
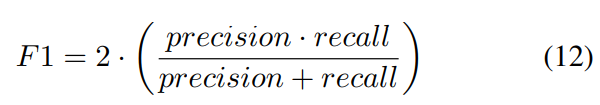
精度定义为$\frac{TP}{(TP + FP)}$,racall被定义为$\frac{TP}{(TP + FN)}$是车道线点的数量,正确预测,FP是假阳性的数量,和FN是假阴性的数量。
4.3 实验结果
本实验进行了一项消融研究来验证本文所有的设计选择。所有消融实验都是在tussimple验证集上进行的,见表2。第一行包含标准LaneAF模型的结果,将其表示为基线模型B。首先,训练没有IoU损失(B w/o IoU)和加权二进制交叉熵损失(B w/o wBCE)的变量。消除这些损失会大大降低准确率,同时增加假阳性和假阴性率。事实上,如果没有加权的二叉交叉熵损失,F1得分会显著下降。在训练期间没有随机转换的基线模型(B w/o RT)也观察到了相同的结果,如第四行所示。
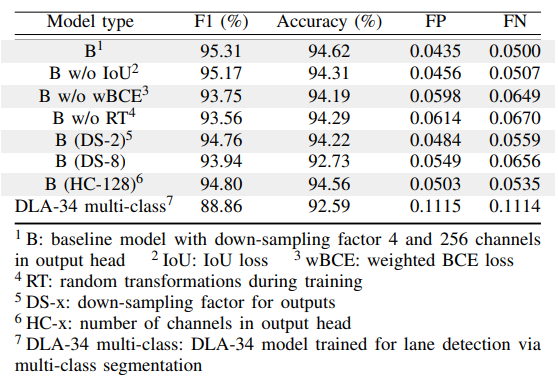
对于输出的降采样因子,可以看出,基线模型的s因子为4的结果最好;将其减少到2 (B (DS-2))会增加运行时间,并略微降低精度和F1,而将其减少到8 (B (DS-8))在所有修改中对精度的破坏性影响最大。本文还在输出头中训练了一个128通道的变体(B (HC-128)),与原始的256通道相比,虽然这个变化的影响最小,但很明显,基准的256通道产生了更好的结果。最后,为了验证本文的聚类方法优于标准的多类分割,本文训练了一个DLA34模型来直接对所有车道进行多类分割(DLA-34多类)。该模型在所有变量中获得了最差的F1和精度分数。结果清楚地说明了使用二值分割和基于亲和场的聚类方法的有效性。
Results
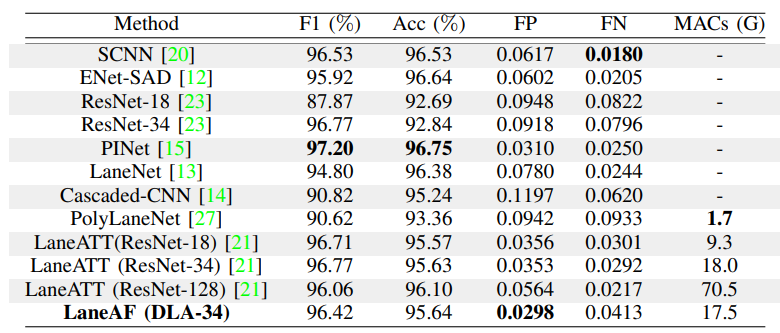
LaneAF在tussimple基准上的性能结果如表III所示。可见,本文的误报率在目前最先进的水平中树立了一个新的标准(0.0298)。这证明了本文的模型不会像其他网络那样错误地检测车道像素,并且LaneAF的多分支方法导致了自信的车道像素预测。虽然本文获得了比其他主干架构(如ResNet-18和34更高的精度,但本文的方法略低于当前最先进的模型(如PINet、ENet-SAD和SCNN)。然而,本文的假阴性率只是略微高一些,这意味着被错误分类的车道像素最有可能位于车道的最末端。
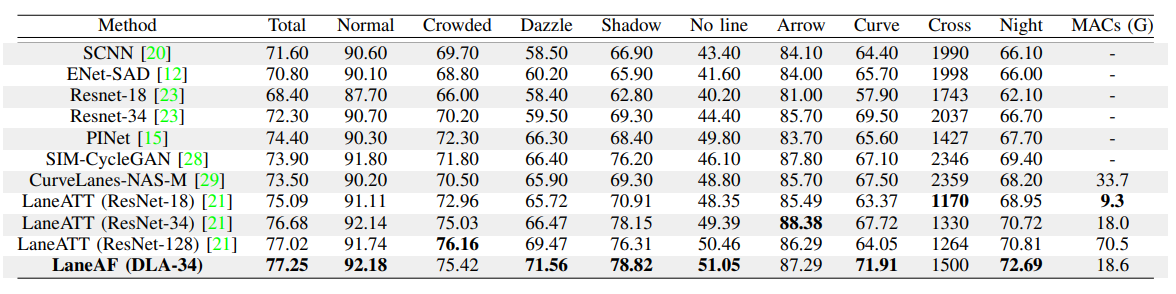
表4显示了本模型在CULane基准上的最新结果。有了这个明显更大更复杂的数据集,可以看到LaneAF的性能比其他模型有了很大的提高,并证明了本文网络的泛化能力。LaneAF以77.25%的F1得分超越了目前最先进的车型,甚至超过了类似尺寸的车型LaneATT拥有最大的主干,ResNet-128。此外,LaneAF为大多数类别设置了一个新的基准,包括复杂的类别,如眩光、阴影、曲线和夜晚,展示了本模型对弯曲的道路和具有挑战性的照明条件的高度适应性。
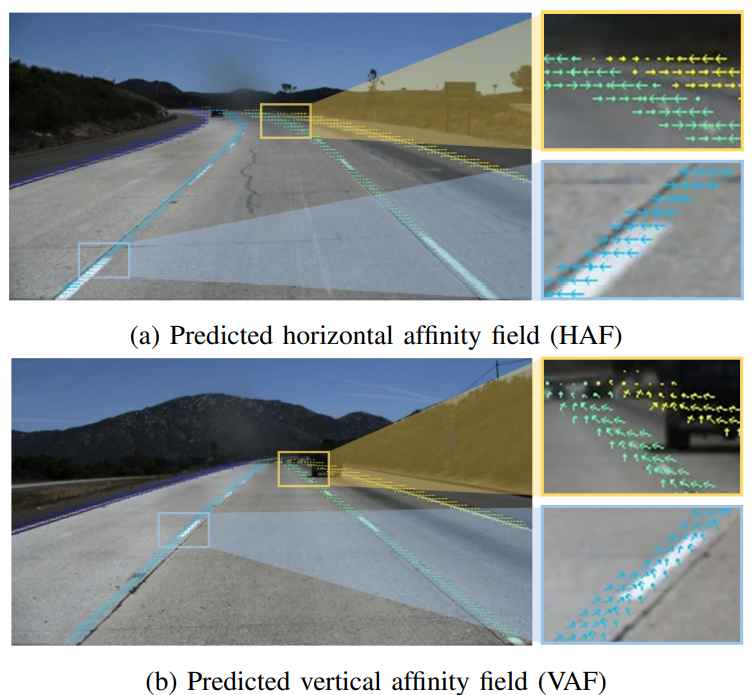
定性结果见图3a和图3b。这里显示的聚集输出是使用亲和域解码器创建的,在算法2中概述了这一点。在图3a中,HAF指向每一行输出图像的车道线的中心。这是基于在二值分割输出中找到的有效车道像素,并表示相对于所有检测到的车道像素的潜在车道实例的位置。车道集群仍然成功分离,尽管它们各自的HAF相邻的许多行,如图3a黄色框所示。同样,在图3b中,VAF沿着车道指向下一行车道像素的平均位置,这是基于HAF输出。这在图3b的黄色框中可见,对于每个独特的车道实例,单位向量指向下一行的平均车道像素位置。对于图3a和图3b,蓝色框清楚地显示了HAF和VAF是如何在单个检测到的车道实例上实现的。
在图4中,显示了第1行TuSimple数据集和第2-4行CULane数据集的其他定性结果。这些简单的例子展示了LaneAF在弯曲公路和因出入口而合并和分裂的车道上的高性能,突出了本文的模型对给定道路上车道数量的灵活性。同样值得注意的是,在第一行中间的图像中,由于飞机的航迹,错误地检测到了一条车道线。CULane展示的结果包括一些具有挑战性的场景,进一步说明了LaneAF在弯曲道路和非常糟糕的照明条件下的鲁棒性。这组不同的示例展示了CULane数据集的眩光、阴影、曲线和夜晚类别的特征。