TensorFlow2.1入门学习笔记(4)——神经网络计算
前面已经学习了有关TensorFlow的一些常用库,以及相关数据的处理方式,下面就是有关神经网络计算的学习笔记。主要学习的资料西安科技大学:神经网络与深度学习——TensorFlow2.0实战,北京大学:人工智能实践Tensorflow笔记
0.1 1.张量(Tensor)的生成
张量可以表示0阶到n阶数组(列表) 张量:多维数组、多维列表 阶:张量的维数
| 维数 | 阶 | 名字 | 例子 |
|---|---|---|---|
| 0-D | 0 | 标量 scalar | s=1 2 3 |
| 1-D | 0 | 向量 vector | v=[1, 2, 3] |
| 2-D | 0 | 矩阵 matrix | m=[[1, 2, 3],[4 ,5 ,6]] |
| n-D | 0 | 张量 tensor | t=[[[(n个“[”) |
数据类型
- tf.int,tf.float…… tf.int32, tf.float32, tf.float64
- tf.bool tf.constant([True,False])
- tf.string tf.constant(“Hello,world!”) 创建一个张量
# tf.constant(张量内容,dtype=数据类型(可选))
import tensorflow as tf
a = tf.constant([1,5],dtype=tf.int64)
print(a)
print(a.dtype)
print(a.shape)运行结果:

将numpy的数据类型转换为Tensor数据类型 tf.convert_to_tensor(数据名, dtype=数据类型(可选))
import tensorflow as tf
import numpy as np
a = np.arange(0,5)
b = tf.convert_to_tensor(a, dtype=int64)
print(a)
print(b)运行结果:

创建特殊张量
- 创建全为0的张量 tf.zeros([个数]维度)
- 创建全为1的张量 tf.ones([行, 列]维度)
- chuangjian全为指定值的张量 tf.fill([n,m,j,k……]维度,指定值)
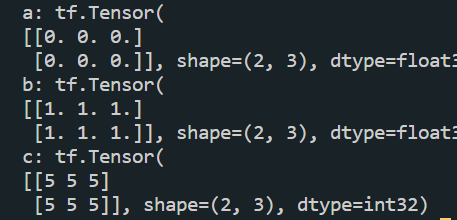
import tensorflow as tf
a = tf.zeros([2, 3])
b = tf.ones([2,3])
c = tf.fill([2, 3], 5)
print("a:", a)
print("b:", b)
print("c:", c)运行结果:
正态分布随机数
- 生成正态分布的随机数,默认均值为0,标准差为1 tf.random.normal(维度,mean=均值,stddev=标准差)
- 生成截断式正态分布的随机数 tf.random.truncated_normal(维度, mean=均值, stddev=标准差) 保证了生成的随机数在$(\mu-2\sigma,\mu+2\sigma)$之内 $\mu:均值, \sigma:标准差$ 标准差计算公式: $\sigma = \sqrt[][\frac{\sum_{i=1}^n{(x_i-\overline{x})^2}}{n}]$
import tensorflow as tf
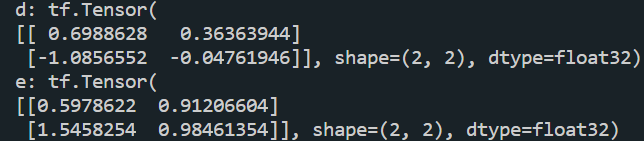
d = tf.random.normal([2, 2], mean=0.5, stddev=1)
print("d:", d)
e = tf.random.truncated_normal([2, 2], mean=0.5, stddev=1)
print("e:", e)运行结果:
生成均匀分布随机数 [minval,maxval) tf.random.uniform(维度, minval=最小值, maxval=最大值)
import tensorflow as tf
f = tf.random.uniform([2, 2], minval=0, maxval=1)
print("f:", f)运行结果:

0.2 2.常用函数
- 强制tensor转换为该数据类型 tf.cast(张量名,dtype=数据类型)
- 计算张量维度上的最小值 tf.reduce_min(张量名)
- 计算张量维度上的最大值 tf.reduce_min(张量名)
import tensorflow as tf
x1 = tf.constant([1., 2., 3.], dtype=tf.float64)
print("x1:", x1)
x2 = tf.cast(x1, tf.int32)
print("x2", x2)
print("minimum of x2:", tf.reduce_min(x2))
print("maxmum of x2:", tf.reduce_max(x2))运行结果:

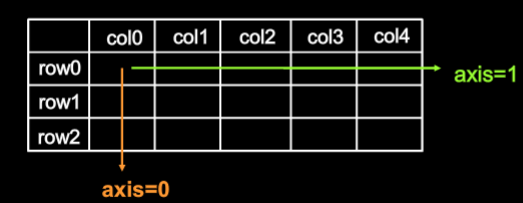
- 理解axis 在一个二维张量或数组中,可以通过调整axis等于1或者1来控制执行维度 axis=0代表跨行(经度,down),而axis=1代表跨列(维度,across) 如果不指定axis,则所有元素参与运算
- 计算张量沿指定维度的平均值 tf.reduce_mean(张量名, axis=操作轴)
- 计算张量沿指定维度的和 tf.reduce_sum(张量名, axis=操作轴)
import tensorflow as tf
x = tf.constant([[1, 2, 3],[2, 2, 3]])
print("x:",x)
print("mean of axis=0:",tf.reduce_mean(x,axis=0)) #计算每一列的均值
print("sum of axis=1:",tf.reduce_sum(x,axis=1)) #计算每行的和运行结果:

- tf.Variable(初始值) 将变量标记为"可训练"的,被标记的变量会在反向传播中记录梯度信息.神经网络训练中,常用该函数标记待训练参数 例如:w = tf.Variable(tf.random.noaml([2,2],mean=2,stddev=1)) 就可以在反向传播过程中通过梯度下降更新参数w
TensorFlow中的数学运算 PS: 只有维度相同的张量才可以做四则运算
- 对应元素的四则运算: tf.add(张量1,张量2,张量3……) tf.subtract(张量1,张量2,张量3……) tf.multiply(张量1,张量2,张量3……) tf.divide(张量1,张量2,张量3……)
import tensorflow as tf
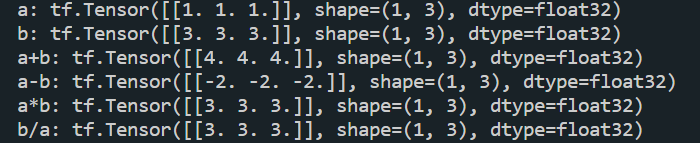
a = tf.ones([1, 3])
b = tf.fill([1, 3], 3.)
print("a:", a)
print("b:", b)
print("a+b:", tf.add(a, b))
print("a-b:", tf.subtract(a, b))
print("a*b:", tf.multiply(a, b))
print("b/a:", tf.divide(b, a))运算结果:
- 平方,次方与开方: tf.aquare(张量1,张量2,张量3……) tf.pow(张量1,张量2,张量3……) tf.sqrt(张量1,张量2,张量3……)
import tensorflow as tf
a = tf.fill([1, 2], 3.)
print("a:", a)
print("a的3次方:", tf.pow(a, 3))
print("a的平方:", tf.square(a))
print("a的开方:", tf.sqrt(a))
- 矩阵乘: tf.matmul(张量1,张量2,张量3……)
import tensorflow as tf
a = tf.ones([3, 2])
b = tf.fill([2, 3], 3.)
print("a:", a)
print("b:", b)
print("a*b:", tf.matmul(a, b))运行结果:

将输入特征/标签配对,构建数据集
- tf.data.Dataset.from_tensor_slices((输入特征,标签)) (Numpy和Tensor格式都可以用该语句读入数据)
import tensorflow as tf
features=tf.constant([12,23,10,17])
labels=tf.constant([0,1,1,2])
dataset=tf.data.Dataset.from_tensor_slices((features,labels))
print(dataset)
for i in dataset:
print(i)运行结果:

with结构记录计算过程,gradient求出张量的梯度 例如: $$\frac{\partial\omega^2}{\partial\omega}=2\omega=2\ast3.0=6.0$$
import tensorflow as tf
with tf.GradientTape() as tape:
x = tf.Variable(tf.constant(3.0))
y = tf.pow(x, 2)
grad = tape.gradient(y, x)
print(grad)运行结果:
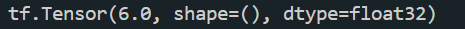
enumerate(列表名) enumerate是python的内建函数,可以遍历每个元素(如列表,元组或字符串),组合为:索引 元素,常在for循环中使用
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i, element)运行结果:

独热编码:tf.one_hot()
tf.one_hot(待转换数据,depth=分几类) 在分类问题中,常用独热码做标签 标记类别:1表示是;0表示非
import tensorflow as tf
classes = 3
labels = tf.constant([1, 0, 2]) # 输入的元素值最小为0,最大为2
output = tf.one_hot(labels, depth=classes)
print("result of labels1:", output)运行结果:

将输出结果转换为概率分布:tf.nn.softmax() 数学表达式:$Softmax(y_i)=\frac{e^y_i}{\sum_{j=0}^ne^y_i}$ 可以使n个分类的n个输出($y_0,y_1,……y_{n-1}$)符合概率分布 $\forall x P(X=x)\in[0,1]且\sum_xP(X=x)=1$
import tensorflow as tf
y = tf.constant([1.01, 2.01, -0.66])
y_pro = tf.nn.softmax(y)
print("After softmax, y_pro is:", y_pro) # y_pro 符合概率分布
print("The sum of y_pro:", tf.reduce_sum(y_pro)) # 通过softmax后,所有概率加起来和为1运行结果:

参数自更新assign_sub()
- 复制操作,更新参数的值并返回。
- 调用assign_sub前,先用tf.Variable定义为变量w为可训练(可自更新) w.assign_sub(w要自减的内容)
$w-=1$
import tensorflow as tf
w=tf.Variable(4)
w.assign_sub(1)
print("w:",w)
返回指定维度的最大值tf.argmax() 返回张量沿指定维度最大值的索引 tf.argmax(张量名,axis=操作轴)
import numpy as np
import tensorflow as tf
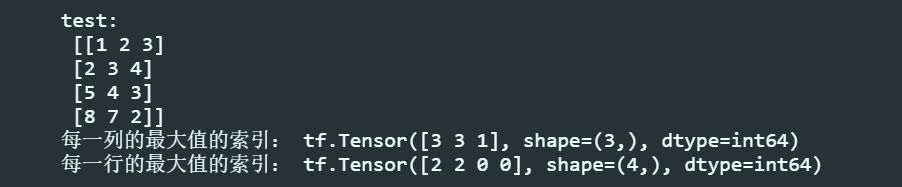
test = np.array([[1, 2, 3], [2, 3, 4], [5, 4, 3], [8, 7, 2]])
print("test:\n", test)
print("每一列的最大值的索引:", tf.argmax(test, axis=0)) # 返回每一列最大值的索引
print("每一行的最大值的索引", tf.argmax(test, axis=1)) # 返回每一行最大值的索引运行结果: