经典算法:Batch Normalization
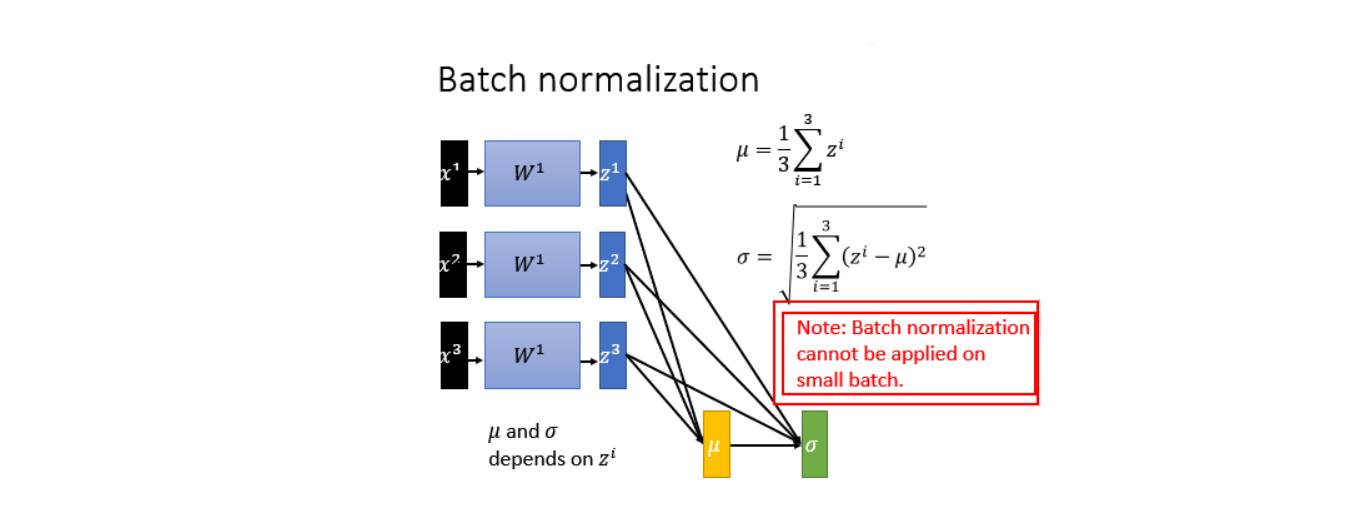
在卷积网络六大模块中的BN(批批标准化)所指的就是Batch Normalization,该算法15年提出,现在已经成为深度学习中经常使用的技术,可以极大的提高网络的处理能力。
1 Feature Scaling 特征缩放
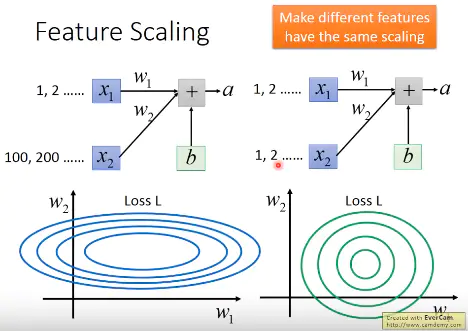
在没有进行Feature Scaling之前,如果两个输入数据$x_1,x_2$的distribution很不均匀的话,导致对$w_2$计算结果的影响比较大,所以训练的时候,横纵方向上需要给与一个不同的training rate,在$w_1$方向需要一个更大的learning rate,$w_2$方向给与一个较小的learning rate,不过这样做的办法却不见得很简单。所以对不同Feature做了normalization之后,使得error surface看起来比较接近正圆的话,就可以使训练容易得多。
优势:
经过处理后error surface更接近一个圆,gradient在横的方向上和纵的方向上变化差不多,使得training变得更容易,如果error suface是一个椭圆,不同的方向上要非常不一样的学习率,例如:在横的方向上给比较大的学习率,纵的方向上给比较小的学习率,给不同的参数不同的学习率是有办法的,但不见得那么好做。如果可以把不同的feature做Normalization,让error surface看起来比较接近正圆的话,是会让training容易得多。
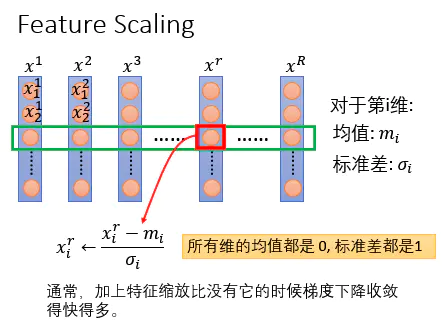
2 经典的Feature Scaling
现在有一大堆的数据,训练数据总共有$R$笔data。然后对每一个dimension去计算dimension的mean跟dimension的standard deviation,假设下图的input是39维,所以就算出39个mean跟39个standard deviation;然后对每一维中的数值,$\frac{x^r_i-m_i}{\sigma_i}$作为一个Normalization,你就使第$i$维的feature的分布为$mean=0,variance=1$。
3 Internal Covariate Shift
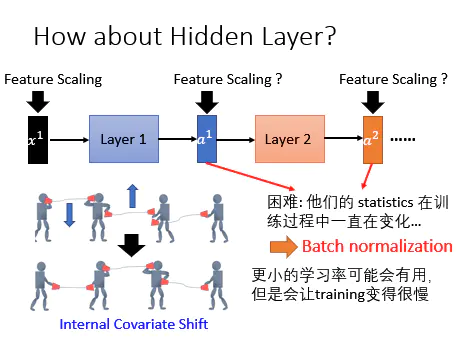
看到上面一排中间那个人,左手边的话筒比较高,右手边的话筒比较低。在训练的时候为了将两个话筒拉到同一个水平高度,它会将左手边的话筒放低一点,同时右手的话筒放高一点,因为是同时两边都变,所以就可能出现了下面的图,最后还是没对上。
在过去的解决方法是调小learning rate,因为没对上就是因为学习率太大导致的,小的learnin rate又会导致训练速度变得很慢。
4 Batch Normalization原理
batch Normalization就是对每一个layer做Feature Scaling,就可以解决Internal Covariate Shift问题。
训练过程参数在调整的时候前一个层是后一个层的输入,当前一个层的参数改变之后也会改变后一层的参数。当后面的参数按照前面的参数学好了之后前面的layer就变了,因为前面的layer也是不断在变的。如果输入normalization的数据,因为输入是固定下来的,具有相同的均值和方差,training就会更容易。
定义网络总共有$L$层(不包含输入层)
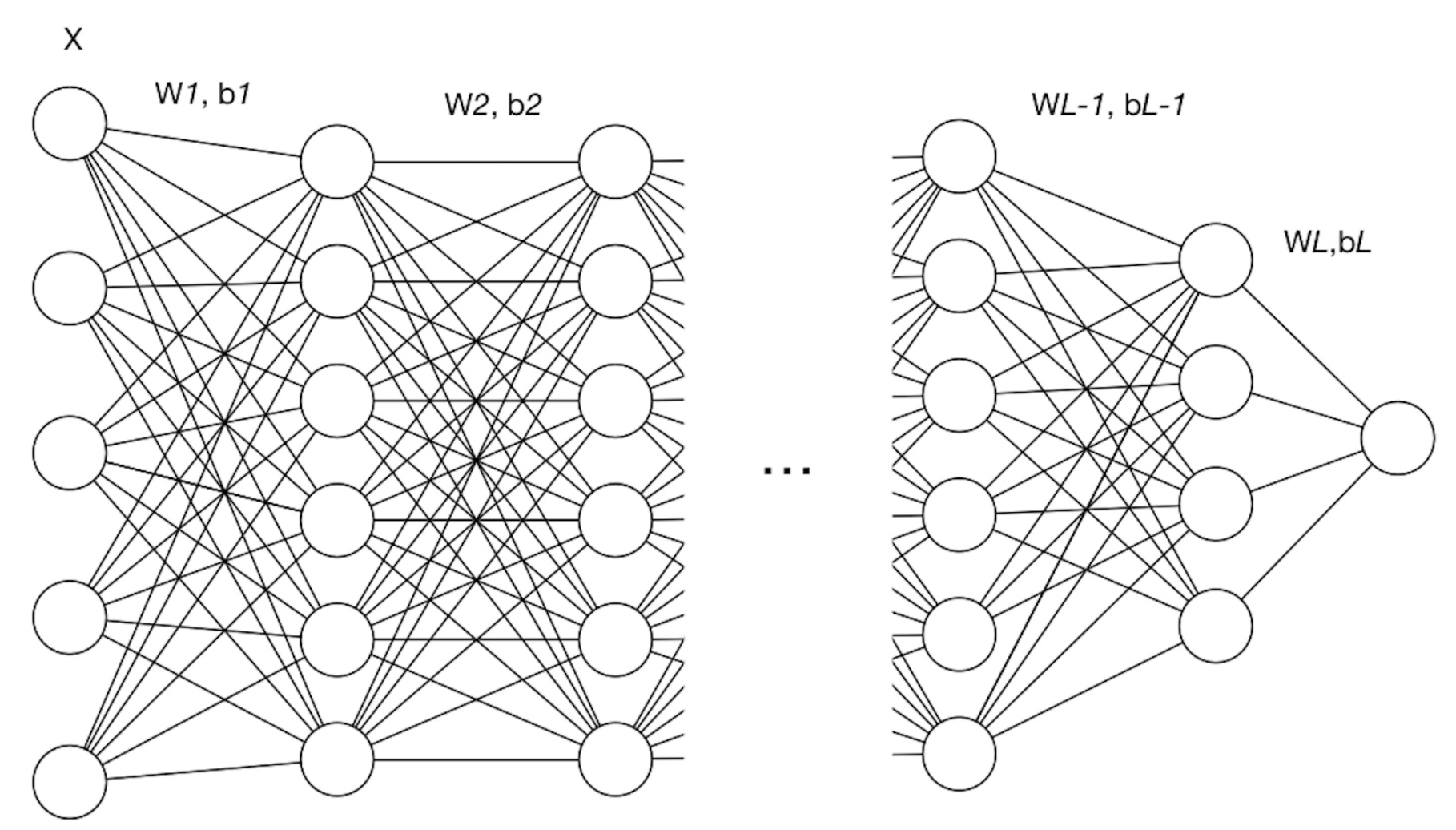
相关参数:
-
$l$ :网络中的层标号
-
$L$ :网络中的最后一层或总层数
-
$d_l$ :第 $l$ 层的维度,即神经元结点数
-
$W^{[l]}$ :第 $l$ 层的权重矩阵, $W^{[l]} \in \R^{d_l\times d_{l-1}}$
-
$b^{[l]}$ :第 $l$ 层的偏置向量, $b^{l}\in \R^{d_l\times 1}$
-
$Z^{[l]}$ :第$l$ 层的线性计算结果,$Z^{[l]}=W^{[l]}\times input +b^{[l]}$
-
$g^{[l]}(\cdot)$ :第 $l$ 层的激活函数
-
$A^{[l]}$ :第 $l$ 层的非线性激活结果,$A^{[l]} = g^{[l]}(Z^{[l]})$
相关样本:
-
$M$ :训练样本的数量
-
$N$ :训练样本的特征数
-
$X$ :训练样本集,$X=\lbrace x^{(1)},x^{(2)}, … ,x^{(M)}\rbrace$ (注意这里 $M$ 的一列是一个样本)
-
$m$ :batch size,即每个batch中样本的数量
-
$X^{(i)}$:第 $i$ 个mini-batch的训练数据, $X=\lbrace x^{(1)},x^{(2)}, … ,x^{(k)}\rbrace$,其中 $X^{(i)}\in \R^{N\times m}$
计算:
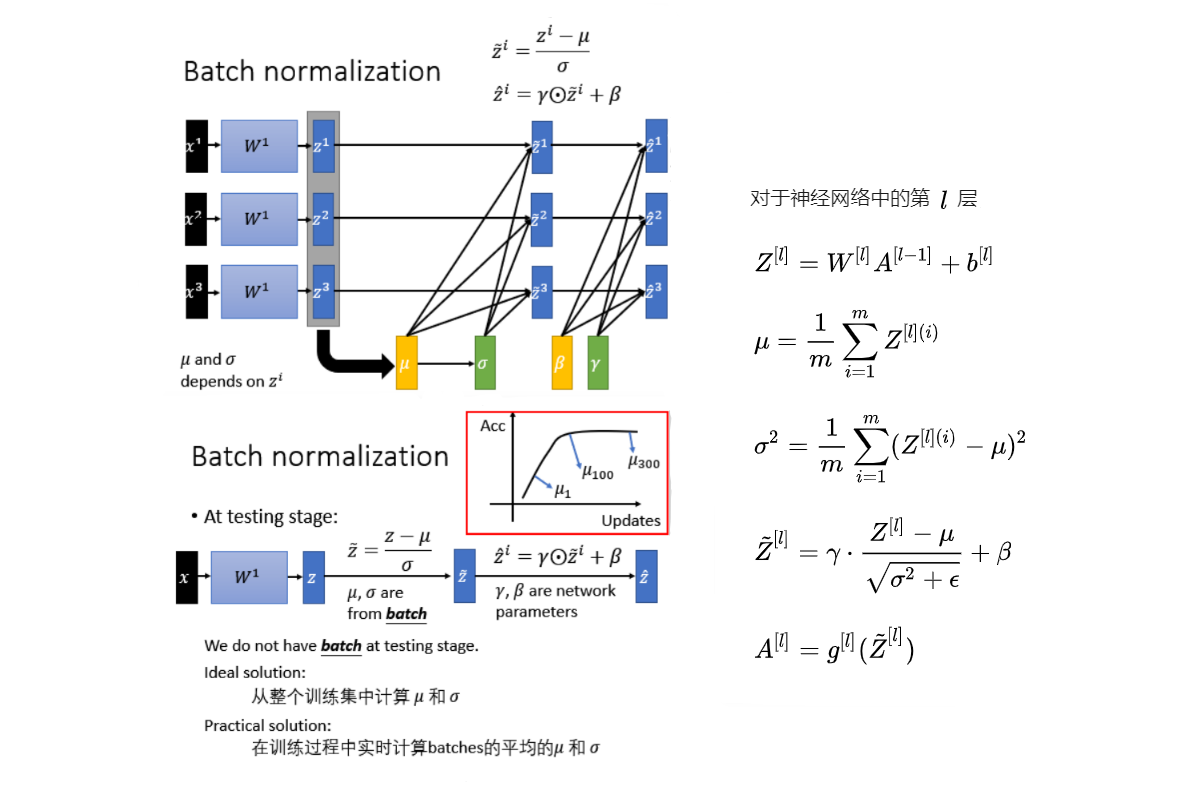
对每个特征进行独立的normalization。考虑一个batch的训练,传入m个训练样本,并关注网络中的某一层,忽略上标 $l$
$$Z\in \R^{d_l\times m}$$
当前层的第 $j$ 个维度,也就是第 $j$ 个神经元结点 ,则有$Z\in \R^{1\times m}$。 当前维度进行规范化:
$$\mu_j = \frac1m\sum^m_{i=1}Z^{(i)}_j$$
$$\sigma^2_j = \frac 1m\sum^m_{i=1}(Z^{(i)}_j-\mu_j)^2$$
$$\hat Z_j=\frac{Z_j-\mu _j}{\sqrt{\sigma^2_j+\epsilon}}$$
其中$\epsilon$是为了防止方差为0产生无效计算。
结合个具体的例子来进行计算: 下图只关注第 $l$ 层的计算结果,左边的矩阵是 $Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]}$ 线性计算结果,还未进行激活函数的非线性变换。此时每一列是一个样本,图中可以看到共有8列,代表当前训练样本的batch中共有8个样本,每一行代表当前 $l$ 层神经元的一个节点,可以看到当前 $l$ 层共有4个神经元结点,即第 $l$ 层维度为4。
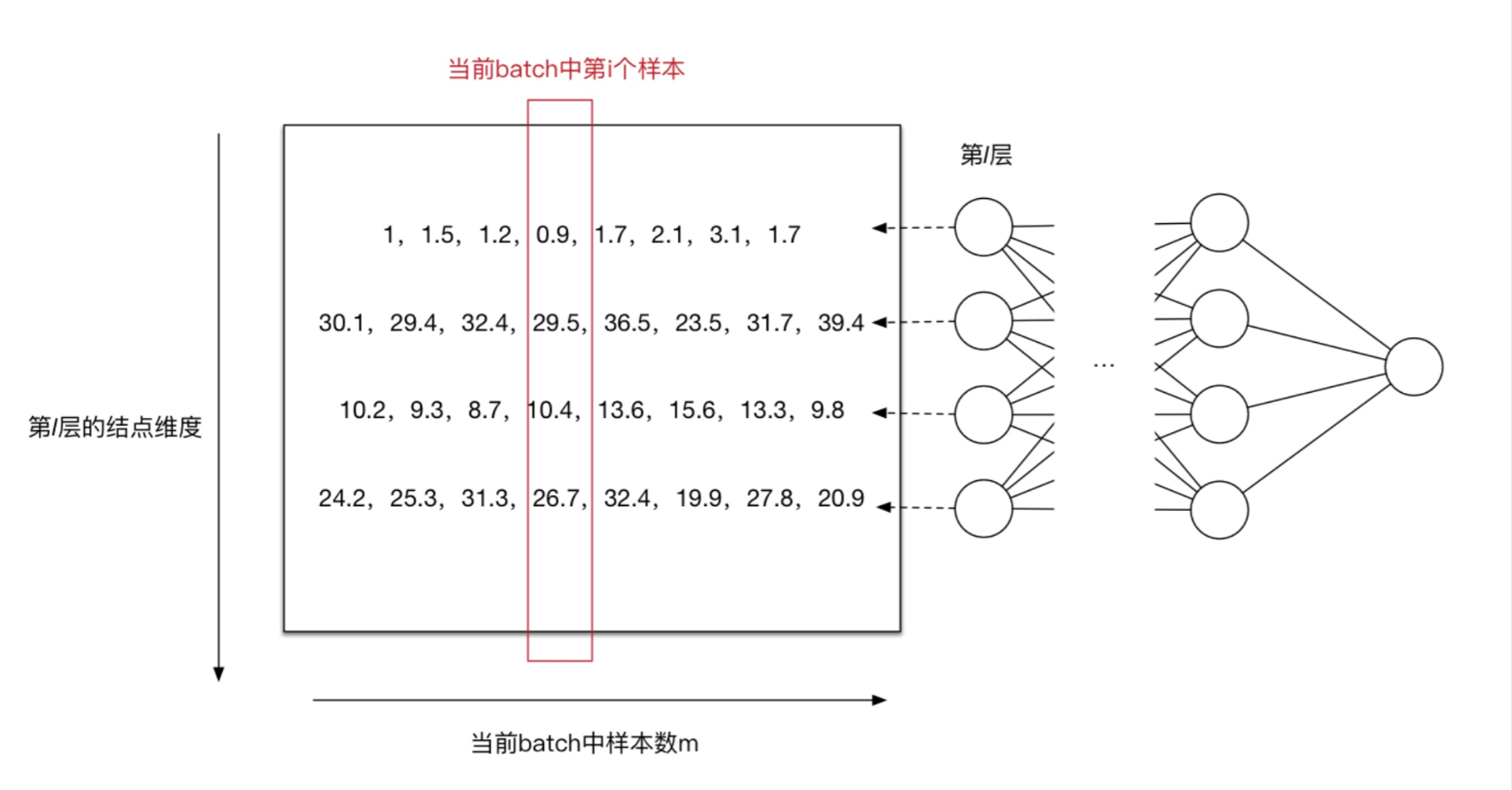
对于第一个神经元,我们求得 $\mu_1 = 1.65, \sigma^2_1=0.44$ (其中 $\epsilon = 10^{-8}$ ),此时我们利用 $\mu_1 ;\sigma^2_1$ 对第一行数据(第一个维度)进行normalization得到新的值 $[-0.98, -0.23, -0.68, -1.13, 0.08, 2.19, 0.08]$ 。同理计算出其他输入维度归一化后的值。如下图:
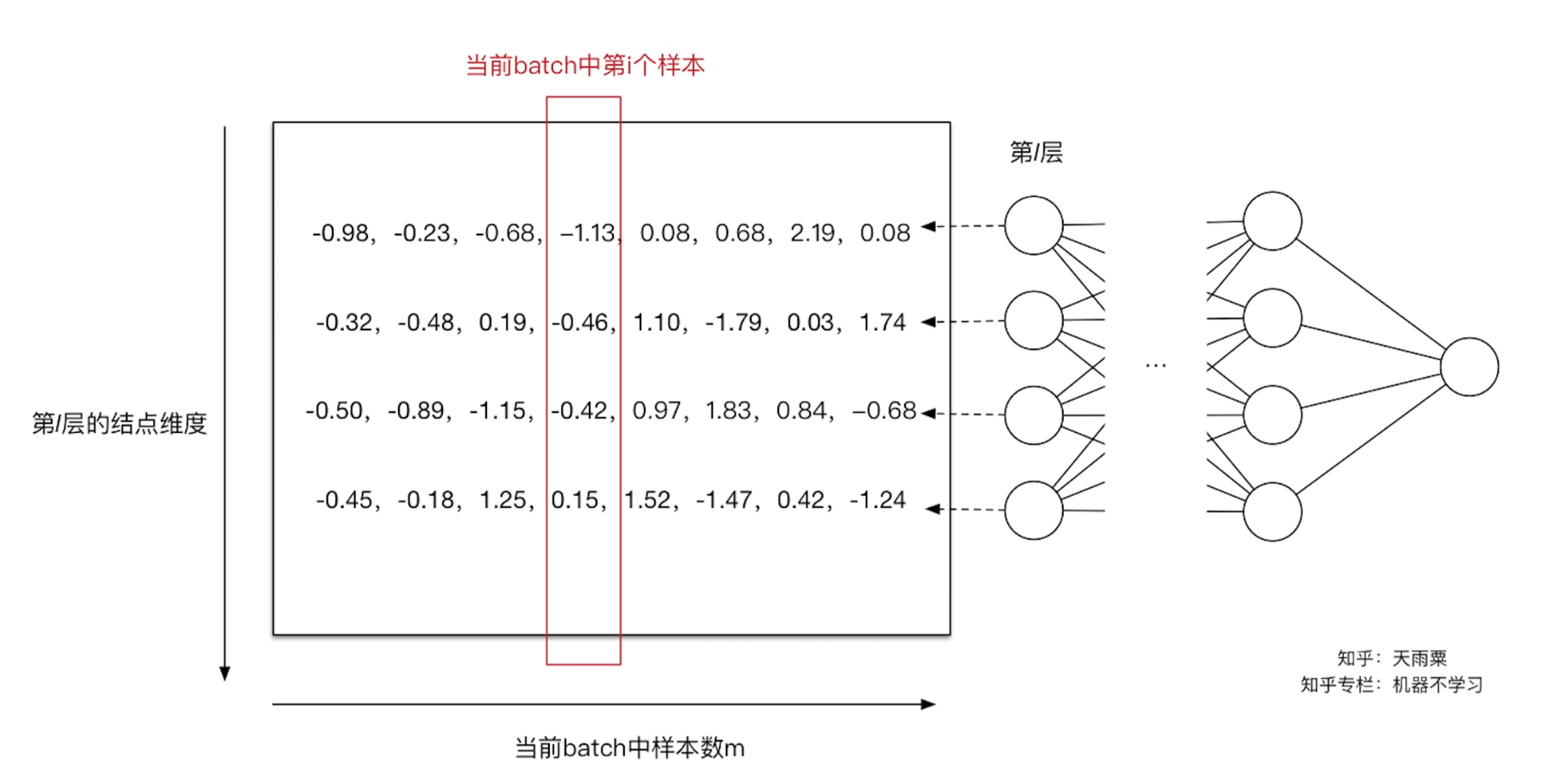
通过上面的变换,用更加简化的方式来对数据进行规范化,使得第 $l$ 层的输入每个特征的分布均值为0,方差为1。
Normalization操作虽然缓解了ICS(Internal Covariate Shift)问题,让每一层网络的输入数据分布都变得稳定,但却导致了数据表达能力的缺失。也就是通过变换操作改变了原有数据的信息表达(representation ability of the network),使得底层网络学习到的参数信息丢失。另一方面,通过让每一层的输入分布均值为0,方差为1,会使得输入在经过sigmoid或tanh激活函数时,容易陷入非线性激活函数的线性区域。
为了解决这个问题,BN又引入了两个可学习(learnable)的参数 $\gamma$ 与 $\beta$ 。这两个参数的引入是为了恢复数据本身的表达能力,对规范化后的数据进行线性变换,即 $\hat Z_j=\gamma_j\hat Z_j+\beta_j$ 。特别地,当 $\gamma^2=\sigma^2,\beta=\mu$ 时,可以实现等价变换(identity transform)并且保留了原始输入特征的分布信息。
补充: 在进行normalization的过程中,由于我们的规范化操作会对减去均值,因此,偏置项 $b$ 可以被忽略掉或可以被置为0,即 $BN(Wu+b)=BN(Wu)$
算法总结:
5 Batch Normalization的优势
-
解决了Internal Covariate Shift的问题:Internal Covariate Shift让学习率需要设很小,Batch Normalization以后学习率可以设大一点,所以training就快一点。
-
对防止梯度消失是有帮助的:用sigmoid函数,你很容易遇到gradient vanish的问题。如果有加Batch Normalization,就可以确保说激活函数的input都在零附近,都是斜率比较大的地方,就是gradient比较大的地方就不会有gradient vanish的问题,所以他特别对sigmoid,tanh这种特别有帮助。
-
对参数的定义的initialization影响是比较小的:很多方法对参数的initialization非常明显,但是当加了Batch Normalization以后,参数的initialization的影响比较小 假设把 $W^1$ 都乘 $k$ 倍, $z$ 当然也就乘上 $k$ ,Normalization的时候, $\mu,\sigma$ 也是乘上 $k$. 分子乘 $k$ 倍,分母 $k$ 乘,做完Normalization以后没有变化。所以如果在initialize的时候, $W$ 的参数乘上 $k$ 倍,对它的output的结果是没有影响。
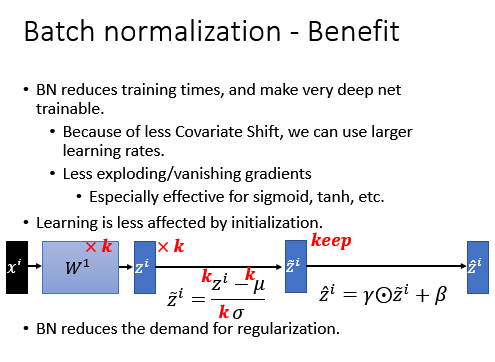
-
能够缓解部分过拟合:在Batch Normalization的时候等同于是做了regularization,这个也是很直观,因为现在如果把所有的feature都固定到一样的mean,variance,如果在test的时候有一个异常数据进来,导致mean有一个变化,但做Normalization就会解决这个问题,所以batch Normalization有一些对抗Over Fitting的效果。所以如果training已经很好,而testing不好,可能也有很多其他的方法可以改进,不见得要Batch Normalization。
参考资源:
