TensorFlow2.1入门学习笔记(15)——循环神经网络,顺序字母预测
Contents
卷积就是特征提取器,通过卷积计算层提取空间信息,例如我们可以用卷积和提取一张图片的空间特征,再把提取到的空间特征送入全连接网络,实现离散数据的分类。但是一些与时间相关的,只可以根据上文预测书下文来预测。
- 例如:

看到这几个字会下意识地想到“水”,这是因为脑具有记忆。记忆体记住了上文中提到的“鱼离不开”这几个字。下意识的预测出了可能性最大的“水”字,这种预测就是通过提取历史数据的特征,预测出接下来最可能发生的情况。
1 循环核
通过不同时刻的参数共享,实现了对时间序列的信息提取。
1.1 具体模型:
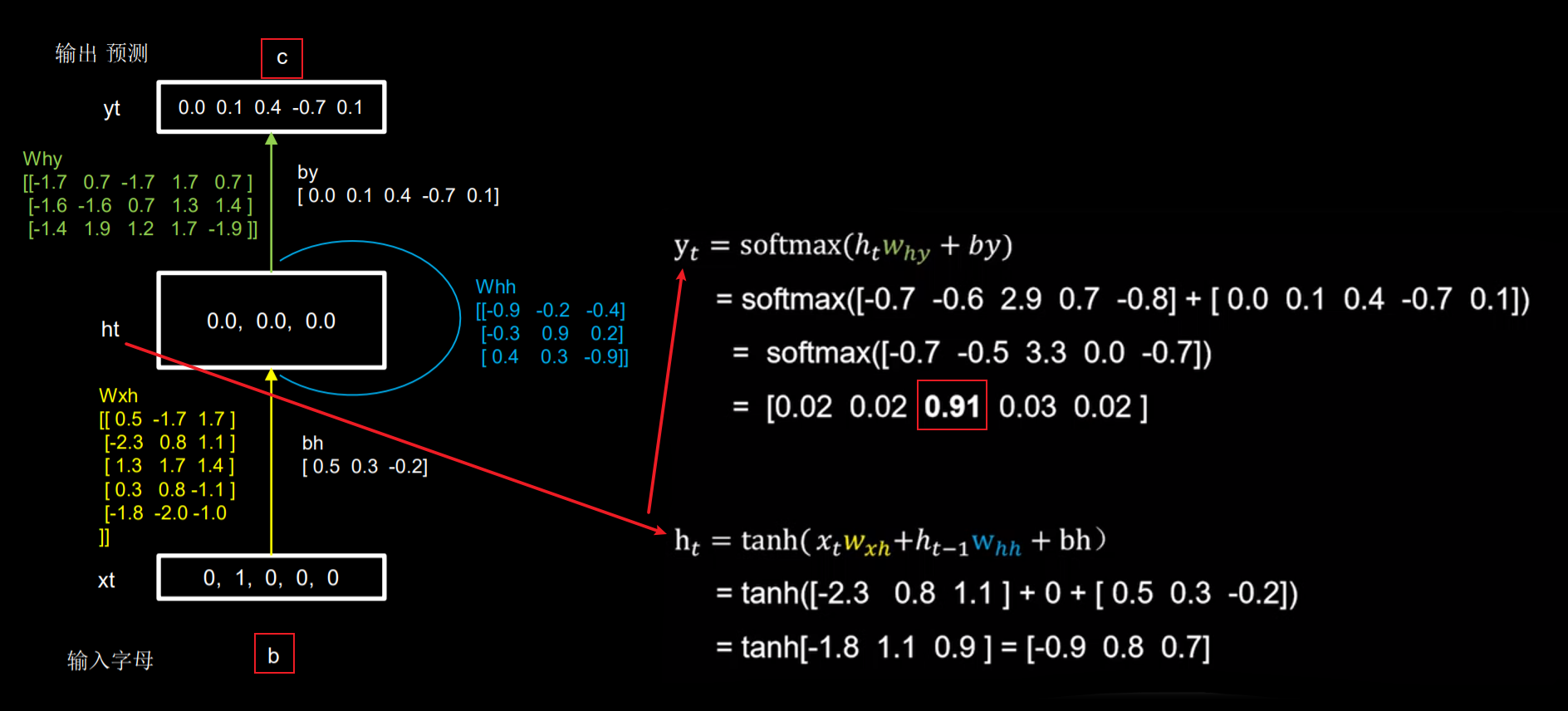
$$y_t = softmax(h_t w_{hy} + b_y)$$ $$h_t = tanh(x_t w_{xh} + h_{t-1}w_{hh})$$
- 输入特征:$x$
- 当前记忆体输出特征:$y_t$
- 当前记忆体存储状态信息:$h_t$
- 上一时刻记忆体存储状态信息:$h_{t-1}$
- 参数矩阵:$w_{xh}, w_{hh}, w_{hy}$
- 偏置项:$b_h$
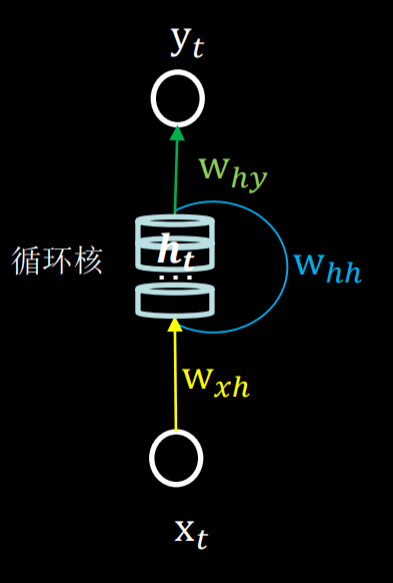
- 前向传播时:记忆体内存储的状态信息$h_t$ ,在每个时刻都被刷新,三个参数矩阵$w_{xh} , w_{hh}, w_{hy}$自始至终都是固定不变的。
- 反向传播时:三个参数矩阵$w_{xh} , w_{hh}, w_{hy}$被梯度下降法更新。
2 循环核按照时间步展开
循环核按时间轴方向展开
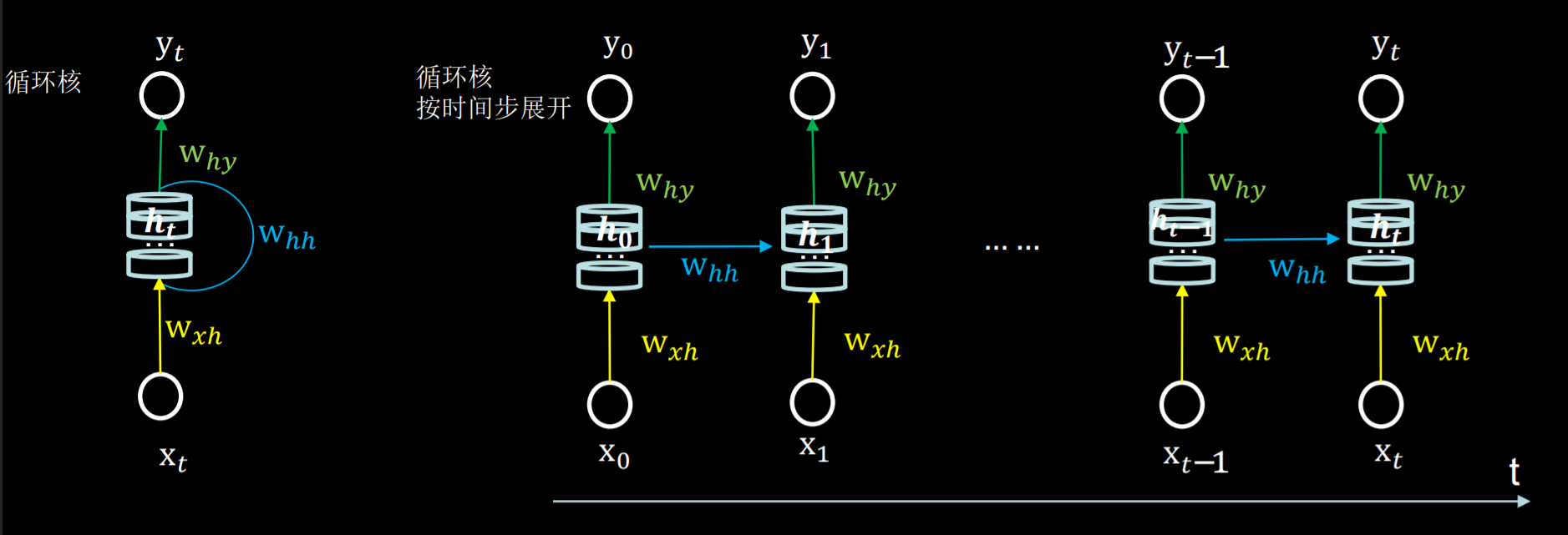
每个时刻$h_t$被刷新,所训练优化的就是三个参数矩阵$w_{xh} , w_{hh}, w_{hy}$,训练完成后使用效果最好的参数矩阵,执行前向传播,输出预测结果。类比人脑的记忆体,每个时刻都根据当前的输入而更新,当前的预测推理是根据以往的知识积累,用固化下来的参数矩阵进行的推理判断。循环神经网络:借助循环核提取时间特征后,送入全连接网络。
3 循环计算层
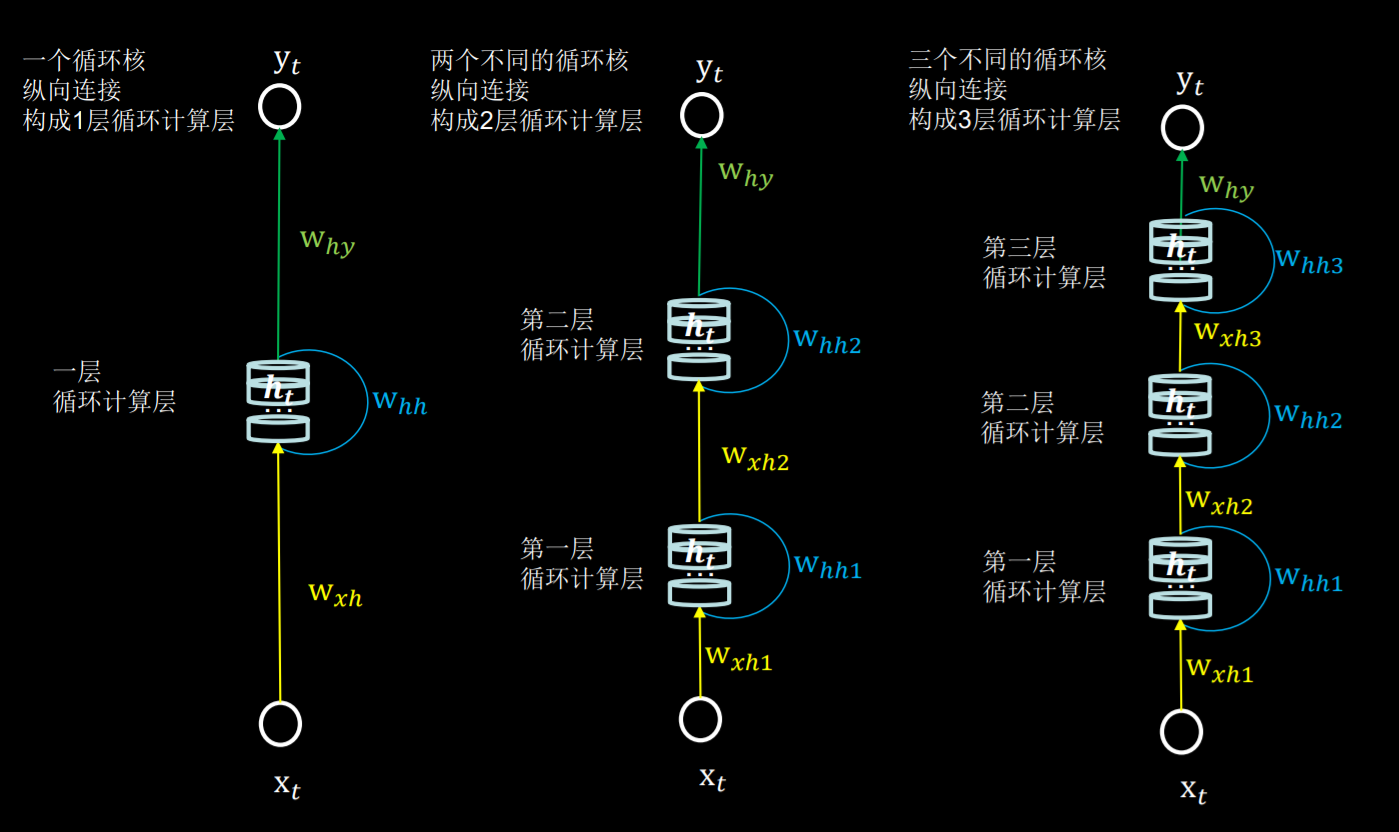
-
每个循环核构成一层循环计算层循环计算的层数是向着输出方向增长的,每个循环核中的记忆体个数是根据寻求来指定的
-
TF描述循环计算层
tf.keras.layers.SimpleRNN(记忆体个数,activation=‘激活函数’ ,return_sequences=是否每个时刻输出ht到下一层)
# 参数
activation=‘激活函数’ (不写,默认使用tanh)
return_sequences=True 各时间步输出ht
return_sequences=False 仅最后时间步输出ht(默认)
# 例:
SimpleRNN(3, return_sequences=True)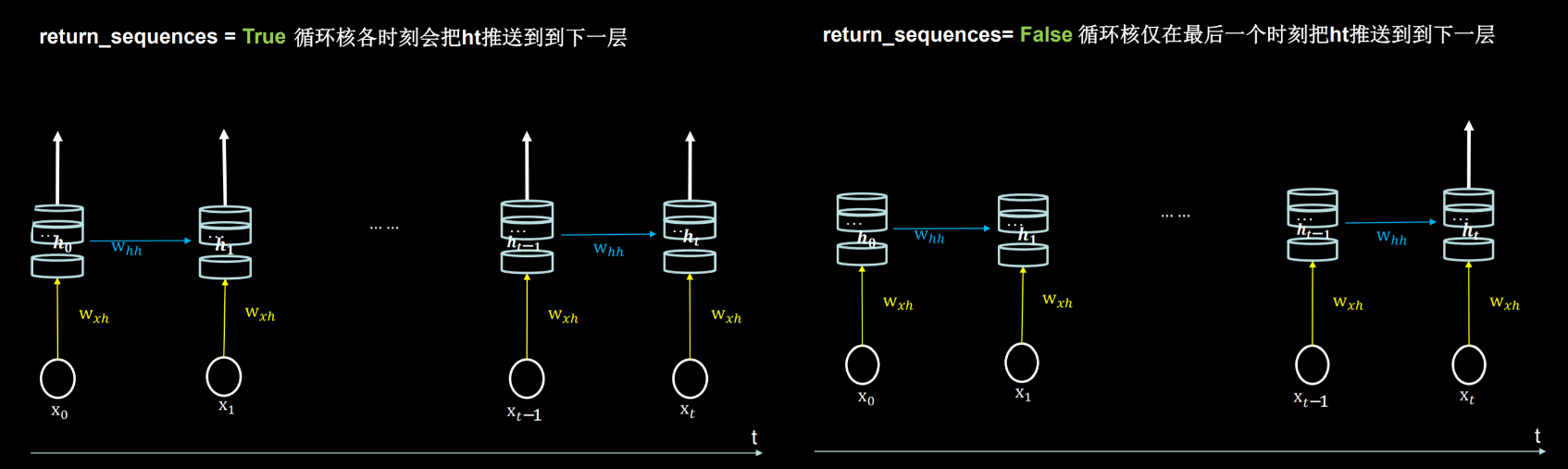
注意: RNN要求输入数据(x_train)的维度是三维的[送入样本数,循环核时间展开步数,每个时间步输入特征个数]
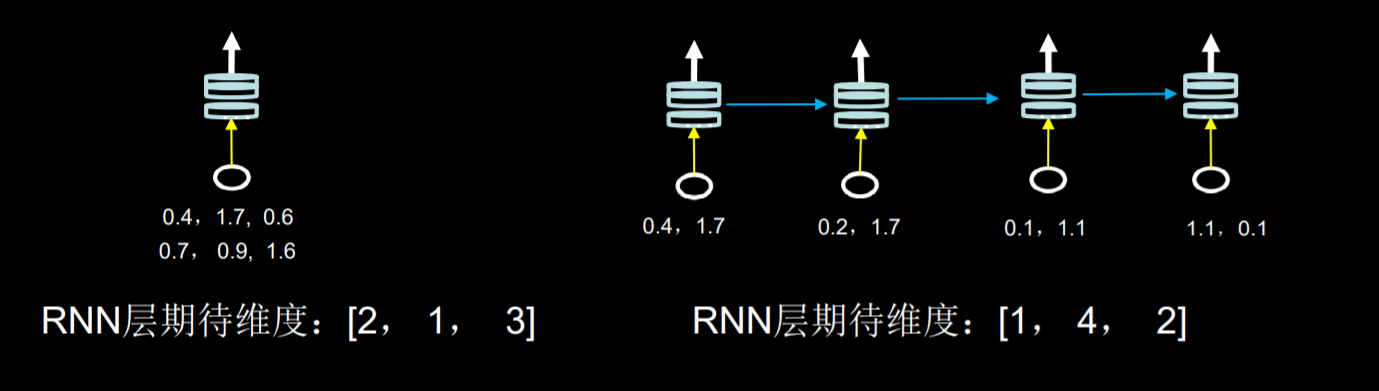
4 循环计算过程
循环网络的输入数据都是数字,因此需要先将数据转换为数字
- 例如字母预测:输入a预测出b,输入b预测出c,输入c预测出d,输入d预测出e,输入e预测出a
使用独热码将字母编码:
| 独热码 | 字母 |
|---|---|
| 10000 | a |
| 01000 | b |
| 00100 | c |
| 00010 | d |
| 00001 | e |
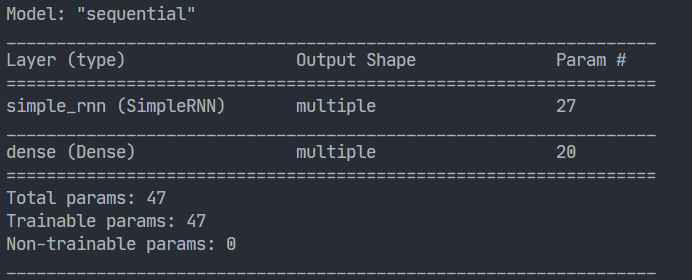
4.1 用RNN实现输入一个字母,预测下一个字母
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, SimpleRNN
import matplotlib.pyplot as plt
import os
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.],
4: [0., 0., 0., 0., 1.]} # id编码为one-hot
x_train = [id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']],
id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]]
y_train = [w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e'], w_to_id['a']]
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 使x_train符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为len(x_train);输入1个字母出结果,循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
x_train = np.reshape(x_train, (len(x_train), 1, 5))
y_train = np.array(y_train)
model = tf.keras.Sequential([
SimpleRNN(3),
Dense(5, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
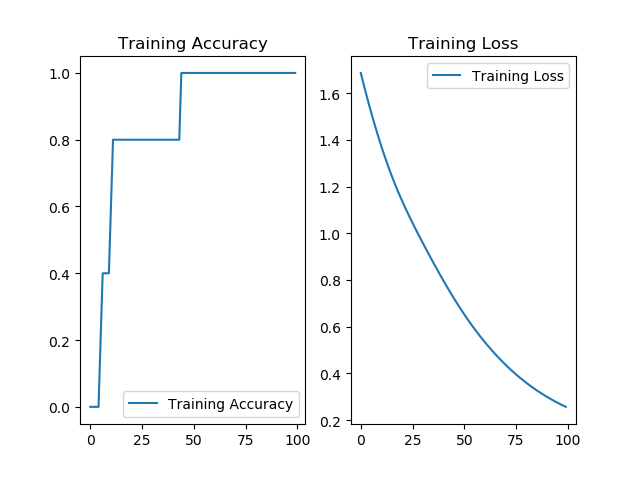
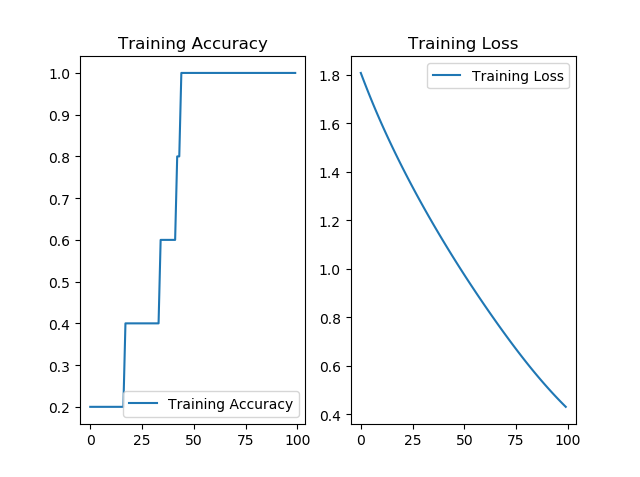
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [id_to_onehot[w_to_id[alphabet1]]]
# 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入1个字母出结果,所以循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
alphabet = np.reshape(alphabet, (1, 1, 5))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
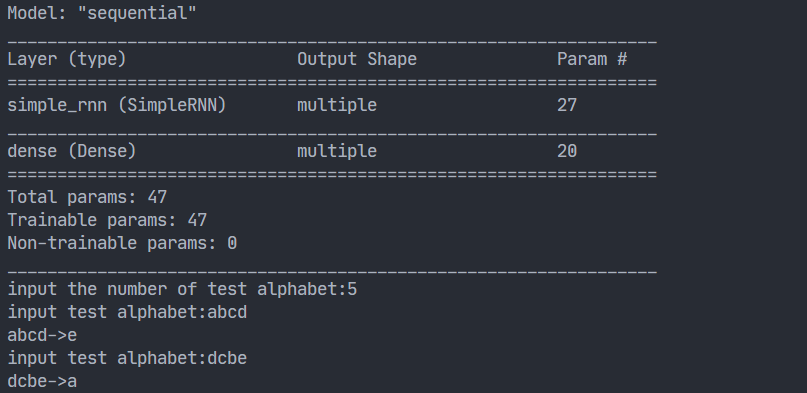
tf.print(alphabet1 + '->' + input_word[pred])- 运行结果
4.2 用RNN实现输入连续四个字母,预测下一个字母
即: 输入abcd输出e 输入bcde输出a 输入cdea输出b 输入deab输出c 输入eabc输出d
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, SimpleRNN
import matplotlib.pyplot as plt
import os
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.],
4: [0., 0., 0., 0., 1.]} # id编码为one-hot
x_train = [
[id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']]],
[id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]],
[id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']]],
[id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']]],
[id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']]],
]
y_train = [w_to_id['e'], w_to_id['a'], w_to_id['b'], w_to_id['c'], w_to_id['d']]
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 使x_train符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为len(x_train);输入4个字母出结果,循环核时间展开步数为4; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
x_train = np.reshape(x_train, (len(x_train), 4, 5))
y_train = np.array(y_train)
model = tf.keras.Sequential([
SimpleRNN(3),
Dense(5, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/rnn_onehot_4pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [id_to_onehot[w_to_id[a]] for a in alphabet1]
# 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入4个字母出结果,所以循环核时间展开步数为4; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
alphabet = np.reshape(alphabet, (1, 4, 5))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])- 运行结果